AIAgent
概念
什么是AI Agent
AI Agent是能够让大语言模型(LLMs)执行操作的系统,通过为 LLMs 提供工具和知识来扩展其功能。
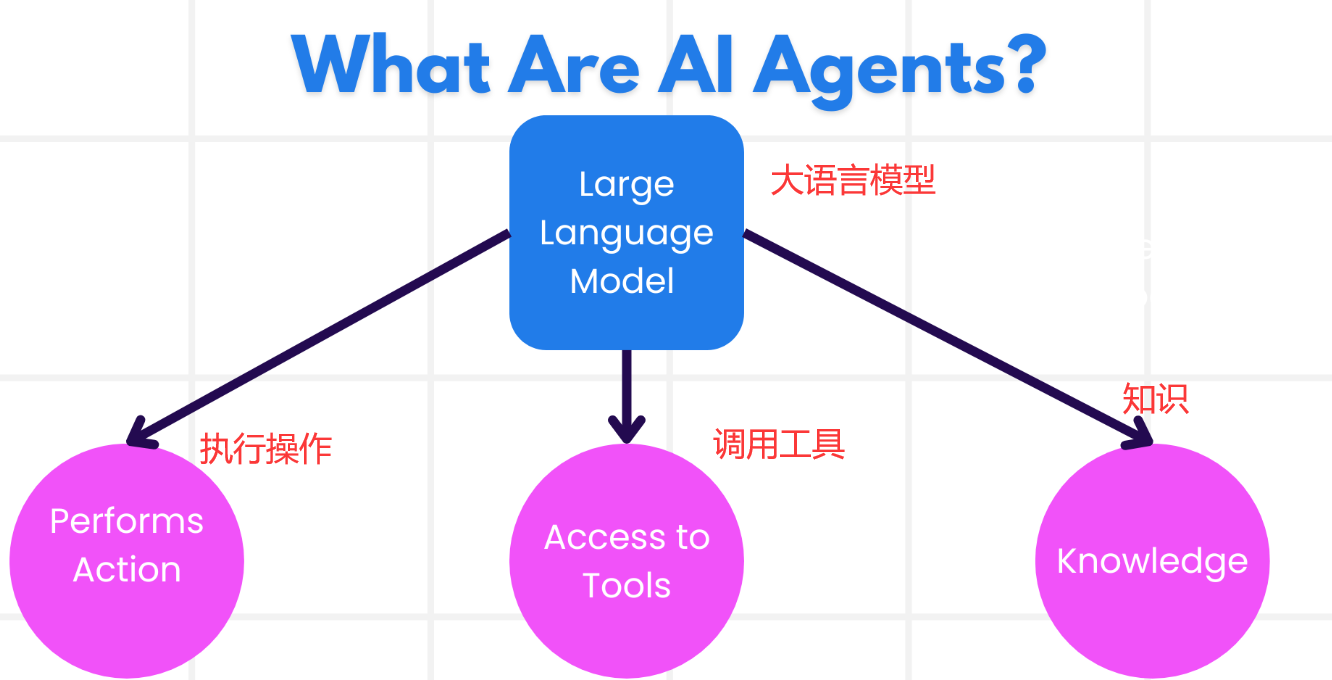
Agent 的任务环境
- 性能度量(Performance):在预算和时间内,最大化用户满意度与合理性
- 环境(Environment):能调用的工具、其他Agent
- 执行器(Actuators):调用函数,展示结果
- 传感器(Sensors):解析输入的数据(工具返回数据、用户输入等)
Agent的运行机制
- 感知(Perception):接收输入(用户或环境来的输入)
- 思考(Thought):大模型推理并制定行动计划,选择要调用的工具
- 行动(Action):执行具体的行动
通过不断地循环上面的步骤,动态调整行动计划
强化学习的框架
智能体(Agent):负责学习和决策
环境(Environment):除Agent外的一切
状态(State):对某时刻的环境的描述
行动(Action):Agent根据当前状态所能采取的操作
奖励(Reward):在智能体执行一个行动后,反馈给智能体的一个标量信号
Agent的学习目标,并非最大化某一个时间步的即时奖励,而是最大化从当前时刻开始到未来的累积奖励
N-gram模型
假定一个词出现的概率只与前有限的N - 1个词有关,N即为上下文窗口大小;
一句话出现的概率为每个词出现概率的乘积;
缺点:
- 语料库中一个词从未出现过,其概率就为0
- 泛化能力差:将词视为孤立、离散的符号,无法理解词与词之间的语义相似性
前馈神经网络语言模型(Feedforward Neural Network Language Model)
用连续的向量来表示词;
将词映射到高维的连续向量空间上的点(Word Embedding),语义相近的词在空间位置上也相近;
常用余弦相似度来计算两个点的关系:
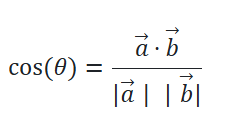
- 两个向量夹角为0°,余弦值为1,完全正相关
- 夹角为90°,余弦值为0,无关
- 夹角为180°,余弦值为-1,完全负相关
解决泛化能力的问题;
缺点:
- 与N-gram类似,上下文窗口是固定的
循环神经网络(Recurrent Neural Network, RNN)
引入了一个隐藏状态(hidden-state)来保存短期记忆,每次读入输入后都会结合之前的隐藏状态来生成新的隐藏状态,并传递给下一刻;
解决固定上下文窗口;
缺点:
- 梯度消失:早期的记忆对后期的影响微乎其微
- 必须按顺序处理数据,无法进行大规模的并行计算
Transformer 架构
抛弃了循环结构,转而完全依赖一种名为注意力 (Attention) 的机制来捕捉序列内的依赖关系,从而实现了真正意义上的并行计算;
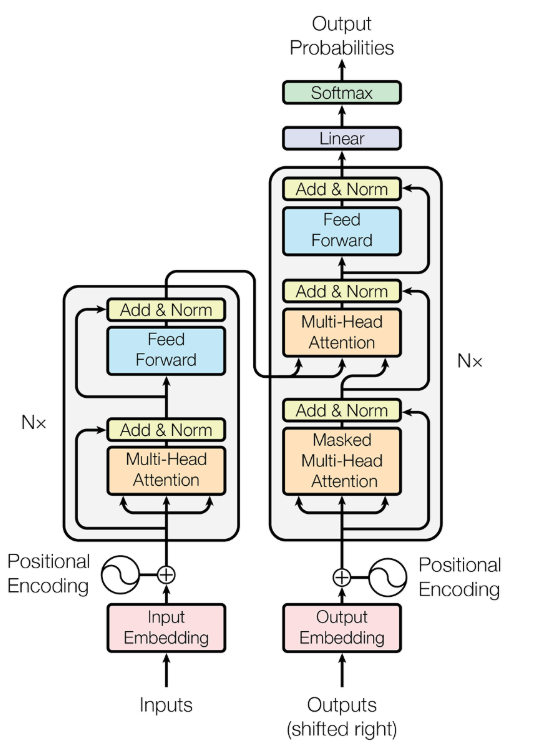
- 编码器:读取所有输入词元,最终为每个词元生成一个富含上下文信息的向量表示
- 解码器:参考自己已经生成的前文,并“咨询”编码器的理解结果,来生成下一个词。
Decoder-Only 架构
只保留了Transformer的解码器部分
自回归:给模型一个起始文本,不断地“回顾”自己已经写下的内容,然后思考下一个字该写什么
Transformer
- 多头注意力模块(Self-Attention):处理序列中每个词时,都能兼顾句子中其他词,为每个词赋予不同的注意力权重;将原始的Q, K, V 向量分成多分,每份分别进行一次单头注意力的计算,从多个角度获取特征关系
- 前馈神经网络模块:作用是从多头注意力模块获取的信息中提取更高阶的特征
- 位置编码模块:注意力机制中没有考虑词元的位置信息。位置编码为输入序列中的每一个词元嵌入向量,都额外加上一个能代表其绝对位置和相对位置信息的“位置向量”
模型采样参数
Temperature:控制模型输出 “随机性” 与 “确定性” 的参数。值越高,会让出现概率低的词也有机会被选中

Top-k:将所有token按概率从大到小排序,只保留前 k 个,把这 k 个的概率重新归一化,之后只在这 k 个里面随机选
Top-p:将所有token按概率从大到小排序,只保留前概率加起来 >= p 的token
提示词技巧
角色扮演:赋予模型一个特定的角色,可以引导它的回答风格、语气和知识范围,使其输出更符合特定场景的需求
你现在是一名资深深度学习工程师,说话简洁、专业、不废话,只给关键结论和代码,不解释多余背景。用户问什么,你都用技术专家的语气回答。
示例:通过在提示中提供清晰的输入输出示例,来“教会”模型如何处理我们的请求,尤其是在处理复杂格式或特定风格的任务时非常有效
把中文翻译成英文,格式如下:
输入:你好
输出:Hello
输入:我在学大模型
输出:I am learning large models
输入:今天天气不错
输出:
我需要你从产品评论中提取产品名称和用户情感。请严格按照下面的JSON格式输出。
评论:这款“星尘”笔记本电脑的屏幕显示效果惊人,但我不太喜欢它的键盘手感。
输出:{“product_name”: “星尘笔记本电脑”, “sentiment”: “混合”}评论:我刚买的“声动”耳机音质很棒,续航也超出了我的预期!
输出:思维链:引导模型一步一步地思考,提升了模型在复杂任务上的推理能力
红球有多少个?
请一步一步思考,先写步骤,再算答案:
- 先设变量
- 列出方程
- 解方程
- 给出最终答案
Agent架构
https://github.com/Xwww12/learn_agent
ReAct (Reasoning and Acting)
一种将思考和行动紧密结合的范式,让智能体边想边做,动态调整。
每次输出都执行三个流程:
- Thought(思考):制定下一步计划
- Action(行动):调用外部工具
- Observation(观察):获取外部工具的返回值
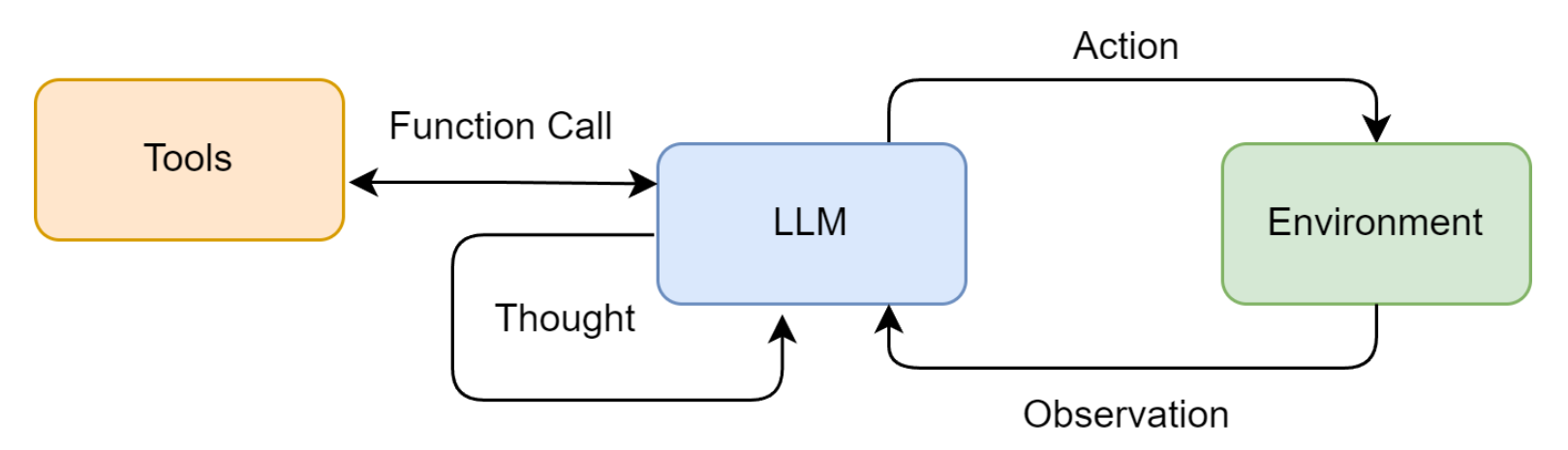
特点:
- 高可解释性
- 动态规划与纠错能力
- 工具协同能力
缺点:
- 对LLM自身能力的强依赖:ReAct 流程的成功与否,高度依赖于底层 LLM 的综合能力。
- 执行效率问题:由于其循序渐进的特性,完成一个任务通常需要多次调用 LLM。
- 提示词的脆弱性:整个机制的稳定运行建立在一个精心设计的提示词模板之上。
- 可能陷入局部最优:步进式的决策模式意味着智能体缺乏一个全局的、长远的规划。
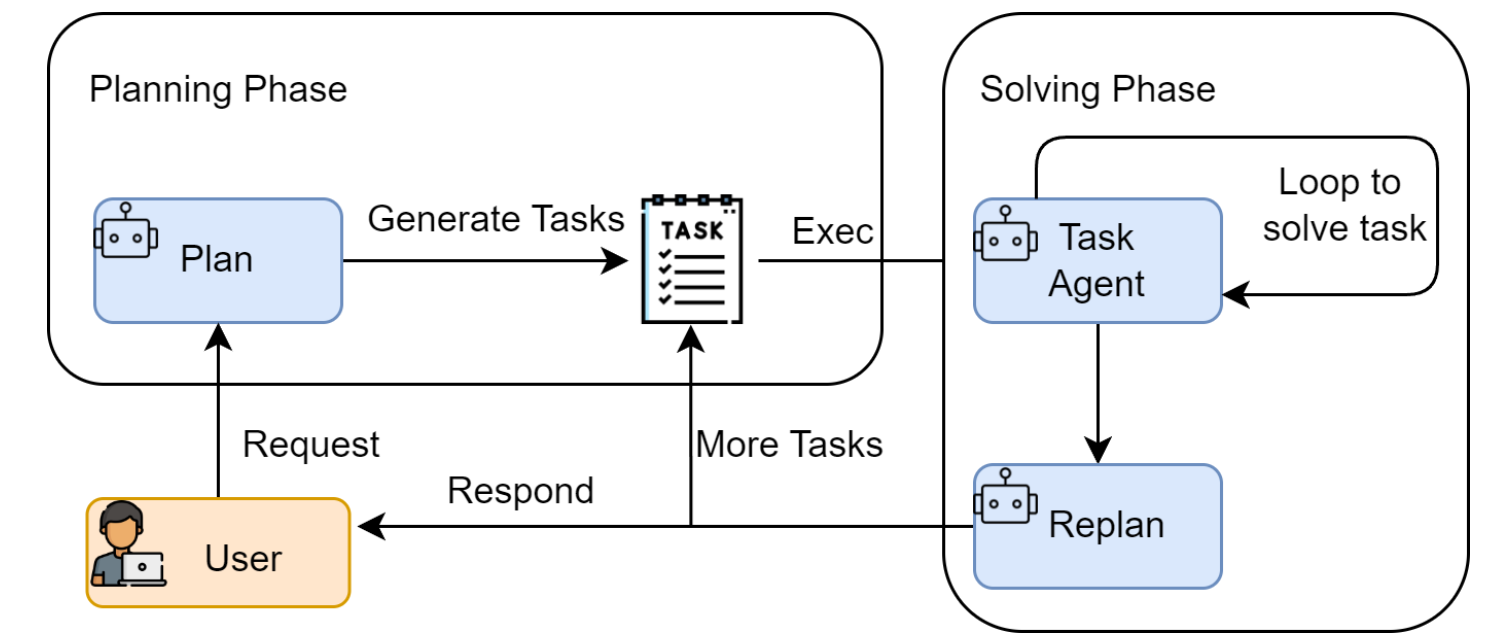
Plan-and-Solve
一种“三思而后行”的范式,智能体首先生成一个完整的行动计划,然后严格执行。
包含两部分:
- 规划器(Planner):生成执行计划
- 执行器(Executor):逐步完成计划,记录每步的执行结果提供给后续步骤
Reflection
一种赋予智能体反思能力的范式,通过自我批判和修正来优化结果。
在前两个架构的基础上,增加一个评审员的角色,对解决方案进行评估和优化
缺点:
- 成本高,每次迭代都要多调用两次llm
- 延迟高
- 复杂度提升
Agent相关库
openai:封装了OpenAI的REST API,用极简 Python 代码调用云端 AI 模型
google-search-results:提供结构化的Google搜索结果
低代码平台
- Coze:字节的低代码平台,官网:https://code.coze.cn/,~~不是很好用~~
- Dify:开源、低代码的 LLM 应用开发与运营平台,官网:https://dify.ai/zh
- n8n:通用的工作流自动化平台,官网:https://n8n.io/
Dify
使用流程:
设置中配置使用的LLM
安装要用的插件
在工作室中创建新的应用,连接各个功能模块
记忆系统
基于LLM的Agent,有两个局限:
- 对话状态的遗忘
- 内置知识的局限
使用到的库
1 | |
使用到的外部服务
Qdrant
ust 编写的开源向量数据库与向量相似度搜索引擎
可以本地部署也可以使用云服务:https://cloud.qdrant.io/
Neo4j
开源图数据库,专门用来存储和查询关系复杂、连接密集的数据
可以本地部署也可以使用云服务:https://neo4j.com/cloud/aura/
Embedding
将文字、图片、声音等转换成向量
阿里的Embedding模型:https://help.aliyun.com/zh/model-studio/dashscopeembedding-in-llamaindex
记忆系统的设计
模仿人类的记忆形成过程,分为:
编码:将感知到的信息转换为可存储的形式
将信息转换为向量
存储:存储编码后的信息
- 工作记忆(working):短期存储当前对话最近的n条上下文
- 情景记忆(episodic):长期存储具体的交互事件和学习经历
- 语义记忆(semantic):存储更为抽象的知识、概念和规则
- 感知记忆(perceptual):存储视觉、听觉等多模态信息
检索:从记忆中提取相关信息
整合:将短期记忆转换成长期记忆
将高重要性的短期记忆转化为长期记忆,或者将长期记忆转换为抽象记忆
遗忘:删除不重要的记忆
- 基于重要性:删除重要性低于阈值的记忆
- 基于时间:删除超过指定天数的记忆
- 基于容量:删除最不重要的记忆
记忆的存储和检索
工作记忆
- 存储:因为是短时记忆,直接存储在内存中
- 检索:计算记忆中的语句和检索词的余弦相似度、检索词在记忆中的语句中的占比、语句的重要性来综合选取
情景记忆
- 存储:长期记忆,使用SQLite + Qdrant来存储
- SQLite:用来存结构化数据,存一份人看得懂的版本
- Qdrant:负责向量检索,存一份转换成向量的版本
- 检索:考虑了语义相似度,还加入了时间近因性的考量,最终通过重要性权重进行调节
语义记忆
- 存储:使用Neo4j + Qdrant的混合架构
- 检索:根据Qdrant存的向量来匹配语义相似度,Neo4j作为关系推理的补充来检索
感知记忆
- 存储:将文本、图像、音频等分开存储,解决维度不统一的问题
RAG
Retrieval-Augmented Generation,检索增强生成
作用:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答
整体工作流程:
- 通过数据提取、文本分割和向量化,将外部知识构建成可检索的数据库
- 响应用户提问时,检索相关信息,注入到prompt中
- 大模型生成答案
创建的具体流程:
- 将传入的任意格式转换成Markdown格式,方便后续统一处理
- 将Markdown文件分块
- 先按段落拆分
- 再根据token数组合/拆分段落,组合成chunk,防止文本太大或太小
- chunk的开头会包含上个chunk的末尾一部分内容,避免语义被硬切断
- 转换成向量存到Qdrant
- 创建完后将加载了这个文档的记忆记录到长期记忆里
高级检索策略:
- 多查询扩展(MQE):将问题的表述方式通过LLM扩展出过个不同的表述方式
- 假设文档嵌入(HyDE):通过LLM生成一个假设性的答案段落,然后用这个答案段落去检索真实文档,减少语义鸿沟
- 扩展检索框架:结合了上述两种方式,系统根据原始查询生成多个扩展查询,然后,对每个扩展查询并行执行向量检索,获取候选文档池;最后,通过去重和分数排序合并所有结果,返回最相关的top-k文档
上下文工程
Context Engineering
为什么需要上下文工程
随着上下文窗口中的 tokens 增加,模型从上下文中准确回忆信息的能力反而下降。
因此,上下文必须被视作一种有限资源,且具有边际收益递减
压缩上下文方法
压缩整合:进行高保真总结,并用该摘要重启一个新的上下文窗口,以维持长程连贯性
适合需要长对话连续性的任务
结构化笔记:Agent以固定频率将关键信息写入上下文外的持久化存储,只保存对应的索引,在后续阶段按需拉回
适合有里程碑/阶段性成果的迭代式开发与研究
子代理架构:由主代理负责高层规划与综合,多个专长子代理在“干净的上下文窗口”中各自深挖、调用工具并探索,最后仅回传凝练摘要
适合复杂研究与分析,能从并行探索中获益
创建上下文
根据GSSC流水线(Gather-Select-Structure-Compress)创建
- Gather:多源信息汇流(记忆系统、RAG等),从多个来源汇集候选信息
- Select(核心):信息选择,根据相关性和新近性对候选信息进行评分和选择
- Structure:结构化输出将选中的信息组织成结构化的上下文模板
- Compress(压缩):对超限上下文进行压缩处理,根据实际任务复杂度动态调整最大上下文大小
结构化笔记
NoteTool,以 Markdown 文件作为载体,头部使用 YAML 前置元数据记录关键信息,正文用于记录状态、结论、阻塞与行动项等内容。这种设计结合了人类可读性、版本控制友好性和易于回注上下文的特性
作用:对于需要长期追踪、结构化管理的项目式任务,我们需要一种更轻量、更人类友好的记录方式。能够跨时间和跨会话保持连贯性
存储格式:Markdown + YAML,进行合理的分类和定期清理与归档
存储内容:一般记录里程碑的节点,如当前阶段的任务状态、进度、总结、遇到的问题和下一步的计划等
使用:检索相关笔记,添加到上下文中
即时文件系统访问
不是预先加载所有文件,而是按需探索和检索。如读代码、日志、数据等。
主要功能:
- 提供给LLM访问文件的方法
- 限制命令的权限
Agent通信协议
提供了一套标准化的接口规范,让智能体能够以统一的方式访问各种外部服务
MCP
Model Context Protocol,标准化智能体与外部工具/资源的通信方式,允许智能体和工具之间共享丰富的上下文信息
工作流程
- 建立与MCP Service的连接
- 发现 能力/工具
- 将工具列表转换为 LLM 能理解的格式,添加到系统提示词中
- LLM 分析用户问题和可用工具,决定是否需要调用工具以及调用哪个工具
- 调用 能力/工具
A2A
Agent-to-Agent Protocol,实现智能体之间的点对点直接通信,每个智能体既是服务提供者,也是服务消费者,类似P2P架构
概念
- 任务(Task):智能体之间委托的单元
- 工件(Artifact):任务产生的结果
- 消息(Message):智能体之间通信的载体
- 部分(Part):消息的组成部分
- Agent Card:描述各个智能体的功能
请求生命周期
- 代理发现:从 A2A 路由 / 注册中心 等检索目标Agent地址
- 身份认证:鉴权
- 发消息 API:一次性请求响应
- 消息流 API:长对话
ANP
Agent Network Protocol,构建大规模智能体网络的基础设施,在大规模网络中发现和连接智能体,让智能体能够动态地发现网络中的其他服务,而不需要预先配置所有的连接关系