LangChain4j
LangChain4j
部署模型
本地部署
下载Ollama
Ollama 是一个可以在本地运行大语言模型(LLM)的工具和平台
步骤:
- 下载:进入官网,点击download,选择对应操作系统下载安装包
- 安装:进入安装包所在文件夹,进入命令行,通过
OllamaSetup.exe /DIR=E:\Ollama指定文件夹安装,否则默认装到C盘 - 设置模型的保存路径:新建一个
models文件夹,添加环境变量OLLAMA_MODELS,值为这个文件夹。为了保险,启动后右击右下角Ollama图标,选择settings,将Model location路径也改一下 - 双击
ollama app.exe启动
命令
| 命令 | 作用 |
|---|---|
| ollama –version | 查看ollama版本 |
| ollama list | 列出已经下载到本地的模型 |
| ollama rm <模型名> | 删除已下载的模型 |
| ollama help | 查看帮助文档 |
| ollama run <模型名> –file <文件名> | 从文件输入 |
| ollama run <模型名> –verbose | 运行时输出日志 |
| ollama run <模型名> –num-gpu 50 | 指定显存分配比例 |
| ollama serve | 启动ollama服务 |
下载模型
步骤:
- 查看模型:进入官网,点击
Models查看模型,后面的…b为参数的数量(单位十亿) - 下载模型:点击需要的模型,复制右上角,在命令行里运行
- 运行模型:下载模型的命令就是运行命令
通过api调用
默认端口11434
输入
1 | |
输出
1 | |
大模型平台
阿里云百炼
- 申请key
- 选择模型,找到示例代码使用
快速使用
版本要求
一定要注意版本,运行时如果提示找不到xxx类,大概率是依赖的版本和SpringBoot不匹配
- JDK >=17
- Spring Boot >= 3.2
使用本地Ollama的模型
https://docs.langchain4j.dev/integrations/language-models/ollama/
引入依赖
1
2
3
4
5
6
7
8
9
10
11<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>ollama</artifactId>
<version>1.19.8</version>
</dependency>测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.ollama.OllamaChatModel;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class DemoLangchain4jApplicationTests {
static String MODEL_NAME = "qwen3:0.6b"; // try other local ollama model names
static String BASE_URL = "http://localhost:11434"; // local ollama base url
@Test
void contextLoads() {
ChatModel model = OllamaChatModel.builder()
.baseUrl(BASE_URL)
.modelName(MODEL_NAME)
.build();
String answer = model.chat("Hello");
System.out.println(answer);
}
}
使用大模型平台的模型
https://docs.langchain4j.dev/get-started
引入依赖
1
2
3
4
5
6
7
8
9
10
11
12<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.5.0-beta11</version>
</dependency>
<!-- 打印日志用的 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.4.14</version>
</dependency>测试
1
2
3
4
5
6
7
8
9
10
11
12
13@Test
void Test() {
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl(在大模型平台里可以找到)
.apiKey(申请的key)
.modelName("qwen-plus")
.logRequests(true)
.logResponses(true)
.build();
String answer = model.chat("Say 'Hello World'");
System.out.println(answer);
}
SpringBoot整合LangChain4j
当前版本为1.5.0-beta11
快速开始
导入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- langChain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.5.0-beta11</version>
</dependency>配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: 自己的key
model-name: qwen-plus
log-requests: true
log-responses: true
server:
port: 8080
logging:
level:
com.xw.consultant: debugcontroller层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import dev.langchain4j.model.chat.ChatModel;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Resource
ChatModel chatModel;
@RequestMapping("/chat")
public String Chat(String msg){
String result = chatModel.chat(msg);
return result;
}
}测试
http://localhost:8080/chat?msg=你好
AiServices工具类
作用是用接口来声明你要的 AI 能力,LangChain4j 会在运行时自动生成实现,调用 LLM 并把结果返回给你
导入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13<!-- LangChain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.5.0-beta11</version>
</dependency>
<!-- LangChain4j AiServices -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.5.0-beta11</version>
</dependency>声明接口
当应用程序启动时,LangChain4j Starter将扫描类路径并查找所有带有注释的接口
@AiService。对于找到的每个 AI 服务,它将使用应用程序上下文中所有可用的 LangChain4j 组件创建此接口的实现,并将其注册为 bean1
2
3
4
5
6
7
8
9
10
11package com.xw.consultant.service;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.spring.AiService;
@AiService
public interface ConsultantService {
@SystemMessage("你是一个有礼貌的助手,每句话前要加上ciallo~")
String chat(String message);
}使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import com.xw.consultant.service.ConsultantService;
import dev.langchain4j.model.chat.ChatModel;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Resource
private ConsultantService consultantService;
@RequestMapping("/chat")
public String Chat(String msg){
String result = consultantService.chat(msg);
return result;
}
}
流式调用
让回答一点点返回,而不是全部生成好了再返回
导入依赖
1
2
3
4
5
6<!-- 流式调用 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.5.0-beta11</version>
</dependency>添加streaming-chat-model的配置信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: 自己的key
model-name: qwen-plus
log-requests: true
log-responses: true
streaming-chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: 自己的key
model-name: qwen-plus
log-requests: true
log-responses: true编写接口
1
2@SystemMessage("You are a polite assistant")
Flux<String> fluxChat(String message);调用
produces = "text/html;charset=utf-8"用来解决乱码问题1
2
3
4
5@RequestMapping(value = "/fluxChat", produces = "text/html;charset=utf-8")
public Flux<String> fluxChat(String msg){
Flux<String> result = consultantService.fluxChat(msg);
return result;
}
消息注解
一般放在接口方法上,或者作为方法参数的注解
@SystemMessage
设定规则、身份、风格、限制
1 | |
@UserMessage
表示用户输入内容,可以对用户内容的前后进行拼接
不用@V("")指定的话,默认为{{it}}
1 | |
会话记忆
为什么要淘汰策略
- 适应LLM的上下文窗口:LLM一次可以处理的token数量是有上限的。 在某些时候,对话可能会超过这个限制。在这种情况下,应该淘汰一些消息
- 控制成本:每个token都有成本,使每次调用LLM的费用逐渐增加。 淘汰不必要的消息可以降低成本
- 控制延迟:发送给LLM的token越多,处理它们所需的时间就越长
使用
MessageWindowChatMemory
通过滑动窗口,保留N条消息,淘汰最旧的消息
通过配置类注入Bean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CommonConfig {
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return new ChatMemoryProvider(){
// 通过指定的id没有找到memory时,会用get方法创建一个,实现会话的隔离
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.build();
}
};
}
}在
AiService注解中声明使用的chatMemoryProvider1
2
3
4
5
6
7@AiService(
chatModel = "openAiChatModel",
chatMemoryProvider = "chatMemoryProvider"
)
public interface ConsultantService {
// 通过注解指定MemoryId和UserMessage
Flux<String> fluxChat(@MemoryId String memoryId, @UserMessage String message);测试
TokenWindowChatMemory
也是通过滑动窗口,于保留最近的N个Token
持久化
ChatMemory通过ChatMemoryStore存储会话记录,默认情况下是存储在内存中的
通过使用自定义的ChatMemoryStore实现持久化
以存到Redis中为例
导入Redis依赖
1
2
3
4
5
6
7
8
9
10
11<!-- Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>添加配置信息
1
2
3
4
5
6
7
8
9
10
11
12spring:
data:
redis:
host: 127.0.0.1
port: 6380
# 默认使用lettuce连接池,要使用jedis连接池需要导入jedis依赖
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000ms编写
ChatMemoryStore实现类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package com.xw.consultant.repository;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import jakarta.annotation.Resource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Repository;
import java.time.Duration;
import java.util.List;
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String json = stringRedisTemplate.opsForValue().get(memoryId.toString());
List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(json);
return list;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
// 将会话信息转化为json格式
String json = ChatMessageSerializer.messagesToJson(list);
// 存储到redis中, 保存时长为1天
stringRedisTemplate.opsForValue().set(memoryId.toString(), json, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
stringRedisTemplate.delete(memoryId.toString());
}
}在
chatMemoryProvider中配置使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21@Configuration
public class CommonConfig {
@Resource
private ChatMemoryStore redisChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return new ChatMemoryProvider(){
// 通过指定的id没有找到memory时,会用get方法创建一个,实现会话的隔离
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(redisChatMemoryStore)
.build();
}
};
}
}
RAG
Retrieval-Augmented Generation,检索增强生成。通过检索外部知识库的方式增强大模型的生成能力
原理
为什么要RAG
- 知识更新滞后:模型训练完成后,参数里的知识是静态的,不能自动更新。
- 记忆有限:模型参数不可能包含所有的事实信息。
RAG基本流程
- 用户输入问题
- 在外部知识库(如向量数据库)检索出相关的文档或片段
- 将问题+检索到的相关文档一起输入给模型
- 模型生成答案
向量数据库
- 是一种 专门用来存储、索引和检索高维向量 的数据库
- 存储格式:不是存“字符串”或者“表格数据”,而是存储一大堆 浮点数向量
- 存储方式:文档被分割成一个个片段,再通过Embedding模型将其转换成一个个高维向量来存储
- 余弦相似度:两个向量夹角的余弦值,重合时为1,垂直时为0,用于计算两个向量的远近
- 检索方式:通过Embedding模型将问题转化为向量,再和数据库中的数据计算余弦相似度,得到文本片段,一起发送给大模型
RAG优点
- 知识实时更新
- 减少幻觉
- 检索范围更可控
使用
Easy RAG
将文档加载在内存中,是RAG的简化实现,用来熟悉概念的
存储
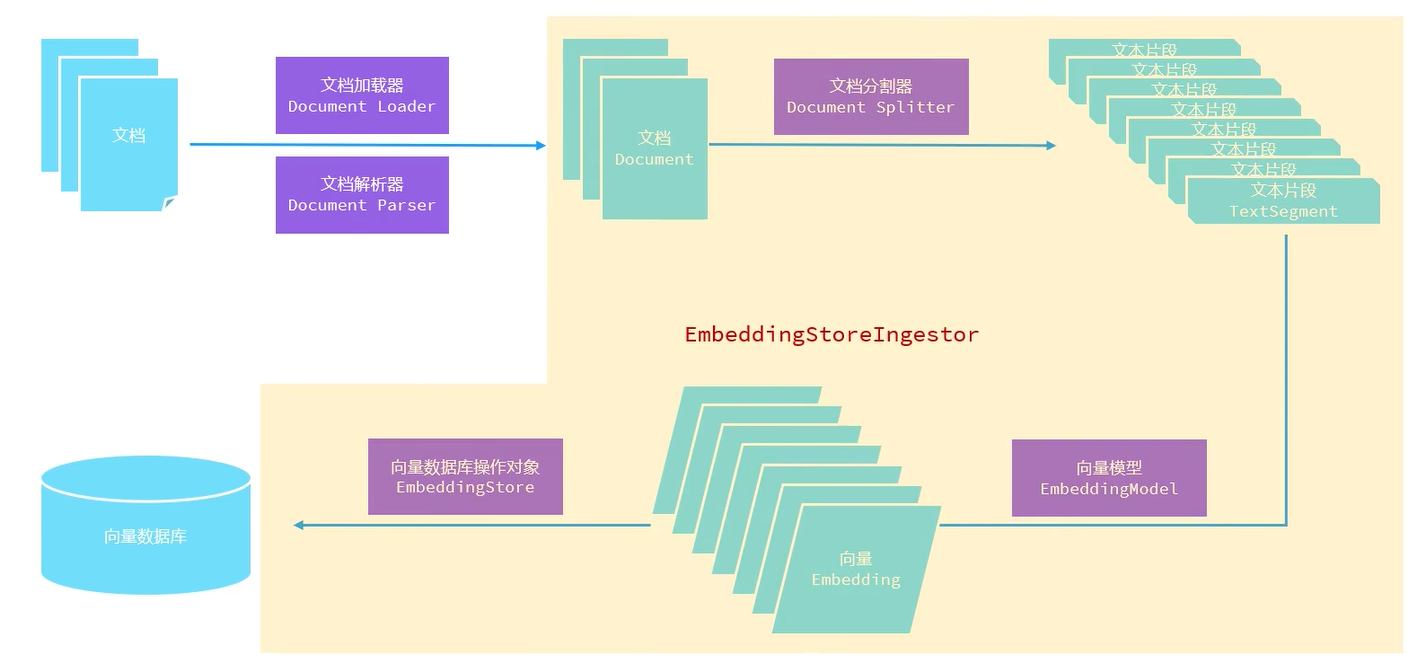
导入依赖
1
2
3
4
5<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.0-beta3</version>
</dependency>构建向量数据库操作对象(只用执行一次就可以将向量存到数据库中,后面可以把@Bean注释掉)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16@Bean
public EmbeddingStore store() {
// 加载文档
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// (内存简化版)向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
// 切割文档并向量化,存储到(内存简化版)向量数据库中
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
// 每个文档片段的最大长度(token),片段之间的重叠部分大小(为了防止硬切导致语义丢失),第一个值太短可能导致没带上有效信息
.documentSplitter(DocumentSplitters.recursive(500, 50))
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}将文档加载进来需要文档加载器和文档解析器,默认的文档解析器几乎可以解析所有的类型,如果要换可以这样做
1
2
3
4
5
6
7<!-- 版本不对可能启动不了 -->
<!-- pdf文档解析器 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>1
2// 在创建文档加载器时指定文档解析器
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());文档分割器的种类,分割的方式有所不同
https://docs.langchain4j.dev/tutorials/rag#document-splitter
Embedding模型用于将文档或用户问题向量化,同样可以替换
1
2
3
4
5
6
7
8embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: 自己的key
model-name: text-embedding-v3
log-requests: true
log-responses: true
# 有些文本向量模型不能一次给太多文本,这里设置批量发送,每次最多发送10个
max-segments-per-batch: 101
2
3
4
5
6// 通过依赖注入获得model对象
@Resource
private EmbeddingModel model;
// 在操作对象和检索对象上都加上
.embeddingModel(model)Embedding Store可以用来指定使用的向量数据库
1
2
3// 将之前的redis容器和镜像删除
// 安装有redisearch模块的redis,让其支持向量搜索
docker run --name redis-vector -d -p 6380:6379 redislabs/redisearch1
2
3
4
5
6<!-- langchain4j对于redis向量数据库的支持 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.5.0-beta11</version>
</dependency>1
2
3
4
5
6# 添加配置信息
langchain4j:
community:
redis:
host: 127.0.0.1
port: 63801
2
3
4
5
6// 依赖注入
@Resource
private RedisEmbeddingStore redisEmbeddingStore;
// 替换操作对象和检索对象使用的Embedding Store
.embeddingStore(redisEmbeddingStore)
检索
构建向量数据库检索对象
1
2
3
4
5
6
7
8
9
10// 构建向量数据库检索对象
// 通过参数进行依赖注入
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5) // 最小的相似度
.maxResults(3) // 查询出来的片段的最大数量
.build();
}配置向量数据库检索对象
1
2
3
4
5
6
7@AiService(
chatModel = "openAiChatModel",
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever" // 配置向量数据库检索对象
)
public interface ConsultantService {
...启动项目有日志信息,文档被切成了几份;测试,查看搜索时是否携带了文档中的信息
1
2
3Documents were split into 29 text segments
Starting to embed 29 text segments
Finished embedding 29 text segments
Tools
让大模型能调用自定义的 Java 方法,扩展它的能力
编写CRUD
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package com.xw.consultant.pojo;
import lombok.*;
import java.time.LocalDateTime;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Setter
@Getter
public class Reservation {
private Long id;
private String name;
private String gender;
private String phone;
private LocalDateTime communicationTime;
private String province;
private Integer estimatedScore;
}编写Tools
@Tool:用于将一个 Java 方法暴露给LLM作为可调用的函数@P:给 AI 提示正确的参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26@Component
public class ReservationTool {
@Resource
private ReservationService reservationService;
// 添加预约信息
@Tool("预约志愿填报服务")
public void addReservation(
@P("考生姓名") String name,
@P("考生性别") String gender,
@P("考生手机号") String phone,
@P("预约沟通时间,格式为: yyyy-MM-dd'T'HH:mm") String communicationTime,
@P("考生所在省份") String province,
@P("考生预估分数") Integer estimatedScore
) {
Reservation reservation = new Reservation(null, name, gender, phone, LocalDateTime.parse(communicationTime), province, estimatedScore);
reservationService.insert(reservation);
}
// 查询预约信息
@Tool("根据考生手机号查询预约单")
public Reservation findReservation(
@P("考生手机号") String phone
) {
return reservationService.findByPhone(phone);
}
}在
AiService注解上添加tools1
2
3
4
5
6
7
8@AiService(
chatModel = "openAiChatModel",
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever", // 配置向量数据库检索对象
tools = "reservationTool"
)
public interface ConsultantService {
...