MySQL
安装
Windows
官网:https://www.mysql.com/downloads/
安装参考:https://blog.csdn.net/qq_59636442/article/details/123058454
Docker
1 | |
- –name mysql:容器名
- -d:后台运行
- -p 3307:3306:端口映射,左边 3307 是宿主机(本机)的端口,右边 3306 是容器里的 MySQL 服务端口
- -e MYSQL_ROOT_PASSWORD=1234:设置容器内 MySQL 的环境变量,这里是
root用户的密码 - mysql:镜像名
MySQL
概念
SQL语言
DDL(Data Definition Language):定义/改变表
DML(Data Manipulation Language):数据的增删改
DQL(Data Query Language):数据的查询
DCL(Data Control Language):设置/更改用户权限
事务的四大特性ACID
原子性:Atomicity,事务是不可分割的最小操作单元
一致性:Consistency,事务完成时,必须使所有的事务都保持一致状态
隔离性:Isolation,事务不受外部影响
持久性:Durability,事务一旦提交或回滚,对数据库的改变是永久的
事务隔离级别
读未提交:可以读到事务未提交的数据
读已提交:只能读到事务已提交的数据
可重复读(默认):限制了读数据的时候不能更改数据,同一事务的多个实例在并发读取数据时,会看到同样的数据行
串行化:事务间串行执行
存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式
不同表可以有不同的存储引擎
MySQL体系结构
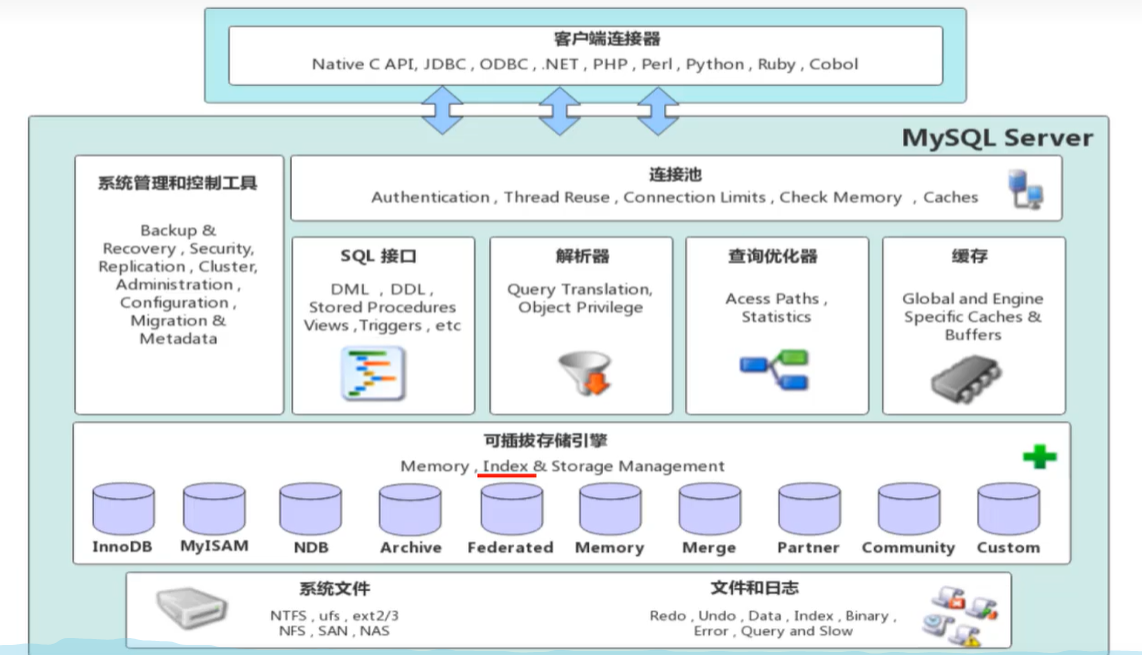
- 连接层:对客户端的连接服务,如连接处理、授权认证等
- 服务层:大多数核心服务功能,如SQL接口、SQL分析和优化、过程、函数等
- 引擎层:负责MySQL中数据的存储和提取,不同的存储引擎具有不同的功能(索引是由存储引擎实现)
- 存储层:将数据存储在文件系统之上
相关命令
查看数据库支持的存储引擎
1
show engines创建表时指定存储引擎(默认InnoDB)
1
2
3
4CREATE TABLE my_myisam(
id INT,
NAME VARCHAR(10)
) ENGINE = MYISAM;
存储引擎特点
InnoDB:
- 支持事务
- 行级锁,提高并发访问度
- 支持外键
- 每一个innodb引擎数据表都对应着一个xxx.ibd文件
MyISAM:
- 早期默认存储引擎
- 不支持事务和外键
- 只支持表锁,不支持行锁
- 访问速度快
Memory:
- 数据存在内存,访问速度快
- 支持hash索引
选择存储引擎
InnoDB:对事务的完整性、并发性要求比较高时
MyISAM:以读操作和插入操作为主,很少更新和删除,对完整性、并发性要求不高时,如日志、评论 –> (MongoDB)
MEMORY:缓存 –>(Redis)
索引
索引是帮助MySQL高效获取数据的数据结构(有序),这种数据结构以某种方式引用(指向)数据。
优缺点
优点:
提高数据检索效率,降低数据库的IO成本
通过索引列队数据进行排序,降低数据的排序成本
缺点:
- 索引需要占用空间
- 需要维护索引,降低了增删改的效率
数据结构
存储引擎主要使用的数据结构有:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型 |
| Hash索引 | 用哈希表实现,只能精确匹配 |
| R-Tree(空间索引) | MyISAM引擎中的索引类型,用于地理空间查询 |
| Full-text(全文索引) | 通过倒排索引,快速匹配文档的方式 |
索引结构:
二叉查找树:左小右大,顺序插入时会形成一棵单叉的树,查询性能大大降低
红黑树:大数据量的情况下,层级较深,检索速度慢
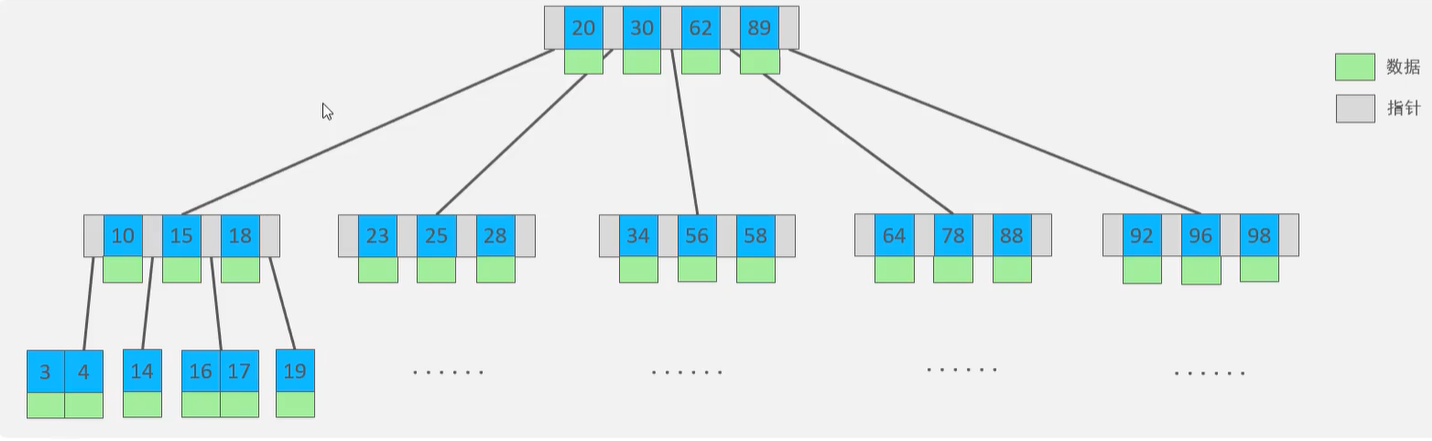
B-Tree(多路平衡树):一个节点下可以有多个子节点
节点的度数:节点的子节点个数;树的度数:最大度数
一个N阶(度数为N)的B-Tree的节点最多可以有N-1个Key,N个指针
构建过程:
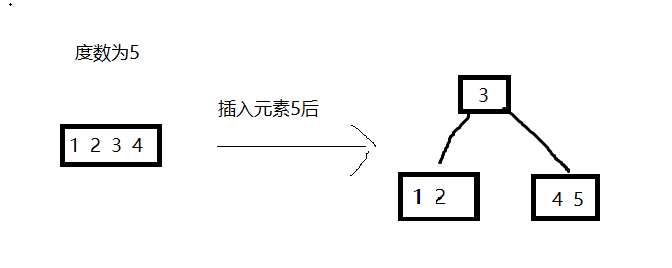
插入一个元素,要插入的节点还放的下的时候按顺序放入节点
放不下时中间元素往上层移动,左右两边分裂成两个节点
上层也放不下时,上层也分裂
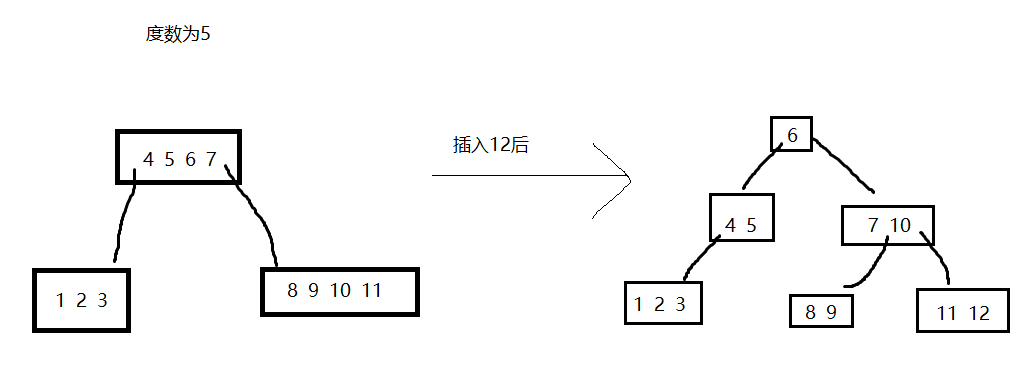
B+Tree:和B-Tree类似,但非叶子节点起到索引的作用,数据都存在叶子节点,叶子结点形成一个单向链表
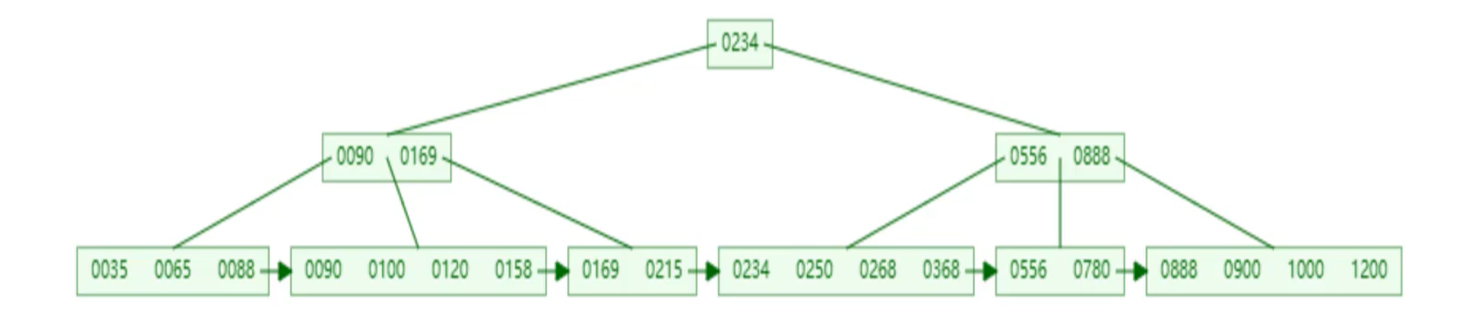
- MySQL和在经典B+Tree上进行了优化,叶子节点形成一个双向循环链表,提高区间访问的性能
Hash:采用一定的hash算法,将键值转换为新的hash值,存储到hash表中
InnoDB使用B+Tree的原因:相对二叉树层级更少;相对于B-Tree,非叶子节点不存放数据,能够放的key更多,层级也就更少;相对于Hash,能支持范围匹配和排序。
分类
根据字段特性分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对主键创建的索引 | 自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免值重复 | 可有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可有多个 | |
| 全文索引 | 通过文本中的关键字查找 | 可有多个 | FULLTEXT |
在InnoDB中,根据索引的存储形式,可以分为
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚簇索引(Clustered Index) | 将数据与索引放到了一块,叶子节点保存了行数据 | 有且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,叶子节点关联的是对应的主键 | 可以存在多个 |
走二级索引需要通过查到的主键回表查询
语法
创建索引
1
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name(index_col_name, ...);查看索引
1
SHOW INDEX FROM table_name;删除索引
1
DROP INDEX index_name ON table_name;
SQL性能分析
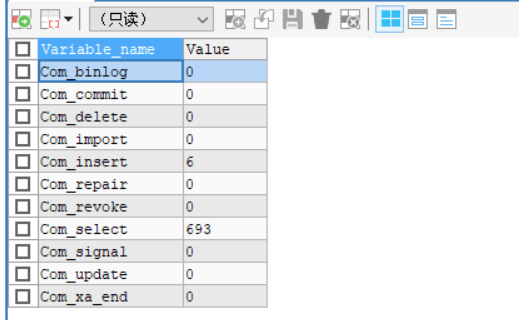
查看当前数据库执行频率
查询频率高的数据库需要优化
1 | |
慢查询日志
记录了所有指定执行时间超过指定参数的所有SQL语句的日志
查看是否开启日志
1
SHOW VARIABLES LIKE 'slow_query_log';开启日志(windows下)
1
2
3# 修改MySQL目录下的my.ini
slow-query-log=1
long_query_time=10日志保存在Data目录下的
xxx-slow.log下
profile
查看每一条sql的耗时情况
查看、开启profile
1
2SELECT @@have_profiling;
SET have_profiling = 1;查看每一条SQL的耗时进本情况
1
SHOW PROFILES;查看指定query_id的SQL语句各个阶段的耗时情况
1
SHOW profile for query_id;
explain
- 在select之前加上explain

字段含义:
- id:表示执行顺序,相同的从上到下,不同的值大的先执行
- type:表示连接类型,性能上从高到低
- NULL
- system
- const:结果只有一条
- eq_ref:唯一索引扫描
- ref:非唯一索引扫描
- range:索引范围扫描
- index:全索引扫描
- all:全表扫描
- possible_keys:字段表示可能用到的索引;
- key:实际用到的索引
- key_len:索引长度
- rows:扫描的数据行数
- filtered:返回结果的行数占读取行数的百分比,越大越好
使用规则
最左前缀法则:联合索引从最左边开始匹配。最左边的列必须有才走索引,如果中间有列不存在,则后面的索引失效。创建联合索引时要考虑顺序
范围查询:联合索引中,出现
>、<范围查询时,之后的索引会失效,>=、<=不会失效索引失效情况:
- 使用
>/<范围查询(>=、<=、BETWEEN AND仍可以使用到索引) - 在索引列上进行运算操作
- 字符串不加引号,存在隐式类型转换
- 在头部进行模糊匹配
- or连接的条件中有没有索引的列时,不管有多少索引,都必须全表扫描搜索这个没有索引的列
- MySQL评估使用索引比全表扫描更慢,则不使用索引
- 使用
SQL提示:
use index:提示优化器建议使用哪个索引
1
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';ignore index:提示优化器不使用哪个索引
1
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';force index:提示优化器必须使用哪个索引
1
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
覆盖索引
查询使用了索引,并且需要返回的列在索引中已经能全部找到,就不需要再回表查询。
如给id和name建立了索引,那
select id,name时就不需要回表查询尽量少使用select *,因为容易回表查询
前缀索引
根据字符串的一部分前缀建立索引,适合大文本
1
CREATE INDEX idx_xxx ON table_name(column(n));可以通过
count(distinct substring(column, m, n))/count(*)来判断适不适合建立前缀索引,值越大越好。
设计原则
- 数据量大(>100w)
- 针对常作为查询条件(Where)、排序(Order By)、分组(Group By)的字段
- 索引把区分度高的字段排在前面
- 较长的字符串字段建立联合索引
- 尽量建立联合索引
- 要控制索引的数量
SQL优化
插入
批量插入,不要一条一条插
1
insert into tb_test valies(1, 'Tome'), ...;手动提交事务,默认是执行一次insert提交一次
1
2
3start transaction;
insert ...
commit;主键顺序插入性能高于乱序
大批量插入数据时用load
1
2
3
4
5
6# 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -uroot -p
# 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile=1;
# 执行load指令将准备好的数据导入,设置字段间分隔符为',',数据间分隔符为'\n'
load data local infile '文件路径.sql' into table `表名` fileds teminatedby ',' lines teminatedby by '\n';
主键
- 满足业务需求的情况下,尽量降低主键的长度
- 尽量不要使用UUID或其他随机的主键,会造成页分裂
- 业务操作时,避免对主键的修改
排序/分组
排序:
Using filesort:通过索引或全表扫描查找出满足条件的数据行,在缓冲区里排序
Using index:通过索引查找出的数据直接就是有序的,效率高
创建联合索引后,如果都按升序或降序排序都是Using index,如果不一样就会Using filesort
可以创建联合索引时指定排序方式来优化
分组:
分组时可以通过索引来提高效率
分组时索引的1使用也满足最左前缀法则
分页
问题:
order by id limit 200000, 10需要查出前200010条数据排序后返回后10条记录,其他数据丢弃,查询排序的代价非常大
解决方式:
使用延迟关联的方式:例如
1 | |
如果直接分页查询,那么查到id后都要回表查询,效率很低;而子查询里分页的话,因为二级索引里有id了,不需要回表查询,减少了回表查询的次数
计数
用法:
- *count()**:返回数据行数 (性能最高,优化器做了优化,不会把值取出来)
- count(主键):返回非空的主键数
- count(某个字段):返回非空的字段数
- count(1):当做每行都是1,记录数据行数
更新
InnoDB的行锁是针对的索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则从行锁升级为表锁
所以更新条件有索引为行锁,没有索引为表锁
视图
视图是张虚表,不保存查询结果,只保存了查询的SQL逻辑
语法
创建
1
2
3
4
5
6
7CREATE [OR REPLACE] VIEW 视图名 AS SELECT 列 FROM 基表 [WHERE...];
# 检查选项:对增删改进行约束
# 后面加 WITH [CASCADED | LOCAL] CHECK OPTION
# 如果是根据视图创建的视图
# CASCADED会检查父视图的条件,不管父视图有没有加CHECK OPTION
# LOCAL只会检查加了CHECK OPTION的父视图的条件查询
1
2
3
4# 查询创建视图的语句
SHOW CREATE VIEW 视图名;
# 查询视图数据
SELECT * FROM 视图名 ...;修改
1
ALTER VIEW 视图名 AS SELECT...;删除
1
DROP VIEW 视图名;插入、更新数据
只有视图的列和基表的列相同时才能更新
存储过程
多条sql的集合
语法
创建
1
2
3
4CREATE PROCEDURE 名称(参数)
BEGIN
-- SQL语句
END;调用
1
CALL 名称(参数);查看存储过程
1
SHOW CREATE PROCEDURE 名称;删除
1
DROP PROCEDURE 名称;声明局部变量
1
2
3
4
5
6
7
8
9
10
11create procedure p1()
begin
# 声明变量
declare stu_count int default 0;
# 第一种赋值方式
set stu_count := 10;
# 第二种赋值方式
select count(*) into stu_count from student;
# 查看
select stu_count;
end;IF
1
2
3
4
5
6
7IF 条件1 THEN
...
ELSEIF 条件2 THEN
...
ELSE
...
END IF;参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29-- 参数类型
-- IN 传入的参数(默认)
-- OUT 输出的参数
-- INOUT 可输入可输出的参数
create procedure p(in score int, out res varchar(10))
begin
if score >= 85 then
set res := '优秀';
elseif score >= 60 then
set res := '及格';
else
set res := '不及格';
end if;
end;
-- 调用
call p(68, @res);
select @res;
-- inout
create procedure p2(inout score double)
begin
set score := score * 0.5;
end;
set @score = 78;
call p2(@score);
select @score;CASE
1
2
3
4
5
6
7
8CASE
WHEN 条件 THEN:
...
WHEN 条件 THEN:
...
ELSE
...
END CASE;WHILE:满足条件继续循环
1
2
3
4
5
6
7
8
9create procedure p(in n int)
begin
declare total int default 0;
while n > 0 do
set total := total + n;
set n := n - 1;
end while;
select total;
end;REPEAT:满足条件退出循环
1
2
3
4
5
6
7
8
9
10
11
12-- 满足条件后退出循环
create procedure p(in n int)
begin
declare total int default 0;
repeat
set total := total + n;
set n ;= n - 1;
until n <= 0
end repeat;
select total;
end;
存储函数
存储函数是有返回值的存储过程,参数只能是IN类型的
1 | |
1 | |
触发器
在增删改之前或之后,触发并执行触发器里的SQL,可用于记录日志、数据校验等
触发器只支持行级触发(即修改一行时触发一次),不支持语句级触发
语法
NEW表示更新之后的数据,OLD表示更新之前的数据
可以选择 BEFORE/AFTER INSERT/UPDATE/DELETE
例子
创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17-- 通过触发器记录user表的变更到user_log表中
create table user_logs(
id int(11) not null auto_increment,
operation varchar(20) comment '操作类型',
operation_time datetime comment '操作时间',
operation_id int(11) comment '操作id',
operation_params varchar(500) comment '操作参数',
primary key('id')
);
CREATE TRIGGER tb_user_insert_trigger
AFTER INSERT ON tb_user for each row
BEGIN
insert into user_logs VALUES
(null, 'insert', now(), NEW.id, concat('插入的数据内容为:id=', NEW.id, 'name=', NEW.name));
END;查看
1
2-- 查看当前数据库的触发器
show triggers;删除
1
DROP TRIGGER tb_user_insert_trigger;
锁
分类
按粒度分
- 全局锁:锁定数据库中的所有表
- 表级锁:每次操作锁住整张表
- 行级锁:每次操作锁住对应的行数据
全局锁
对整个数据库实例加锁,加锁后整个实例就处于只读状态,后续的DML、DDL和事务提交语句都会被阻塞
使用场景:全库的逻辑备份,保证数据的一致性
1 | |
1 | |
表级锁
表级锁主要分为三类:
- 表锁
- 共享锁
- 写锁
- 元数据锁(meta data lock)
- 意向锁
表锁
语法
加锁
1
lock tables 表名... read/write;释放锁
1
unlock tables;
元数据锁
是给表结构自动加的锁,在增删改查时加MDL读锁,在修改表结构时加MDL写锁
意向锁
当要加表锁的时候,需要去查看是否加了行锁,一行行查效率太低
意向锁就是为了提高性能的
在加行锁的时候会加上意向锁,其他线程加表锁的时候就不用一行行判断了
意向共享锁:和表锁共享锁兼容
意向排他锁:和表锁共享锁和排他锁都不兼容
行级锁
每次操作锁住对应的行数据,粒度最小,并发度最高,是对索引加的锁
行锁
增删改时自动加行级排他锁
SELECT 不加锁
SELECT … LOCK IN SHARE MODE 加共享锁
SELECT … FOR UPDATE 加排他锁
记录锁/间隙锁/临键锁
记录锁:锁住当前记录
间隙锁:把两个索引之间不存在的索引锁住,锁住后插入语句会被阻塞,防止幻读
临键锁:记录锁+间隙锁,左开右闭
注意
在 MySQL 的可重复读隔离级别下,针对当前读的语句会对索引加记录锁+间隙锁,这样可以避免其他事务执行增、删、改时导致幻读的问题
锁退化的情况
- 等值查询
- 唯一索引:记录存在时退化成记录锁,不存在时退化成间隙锁
- 非唯一索引:对第一个不符合要求的记录退化成间隙锁
- 范围查询
- 唯一索引在满足一些条件的时候,索引的 next-key lock 退化为间隙锁或者记录锁。
- 非唯一索引范围查询,索引的 next-key lock 不会退化为间隙锁和记录锁。
- 在执行 update、delete、select … for update 等具有加锁性质的语句,一定要检查语句是否走了索引,如果是全表扫描的话,会对每一个索引加 next-key 锁,相当于把整个表锁住了
InnoDB引擎
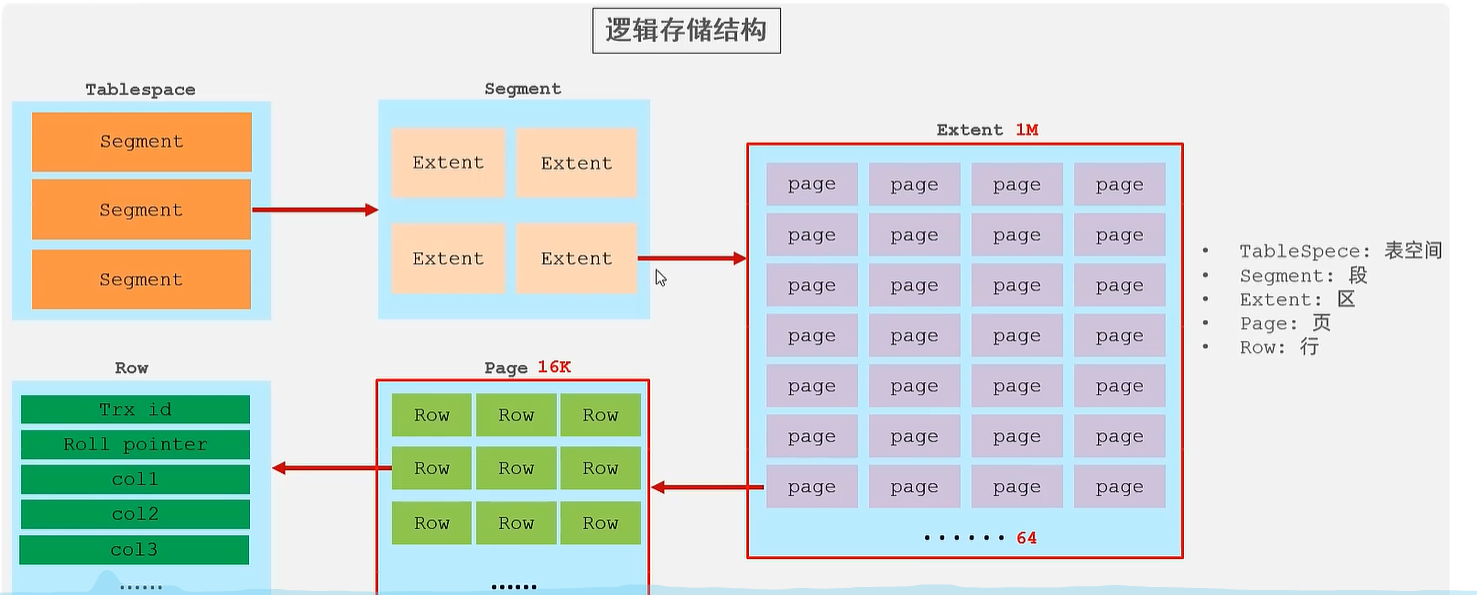
逻辑存储结构
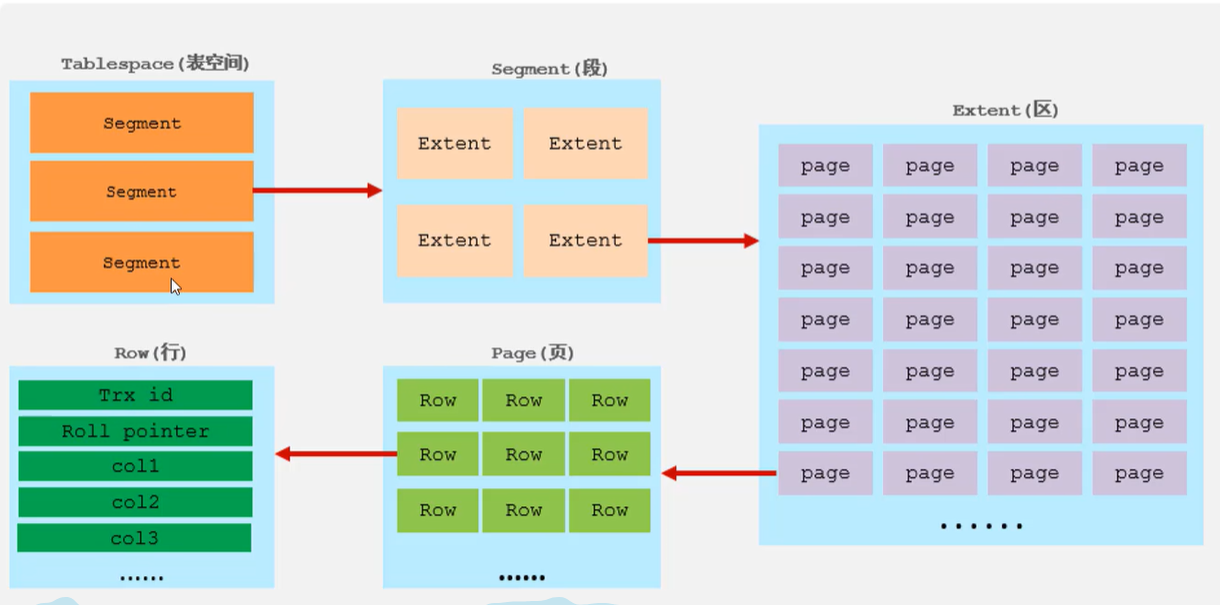
- 表空间(ibd文件):一个mysql实例(database)对应多个表空间,用于存储记录、索引等数据
- 段:数据段是B+数的叶子结点,索引段是B+数的非叶子节点
- 区:大小为1M
- 页:大小为16k,存储引擎管理的最小单位
- 行:数据是按行存放的
架构
内存架构

Buffer Pool(缓冲池):缓存磁盘中经常操作的真实数据,按一定频率刷回磁盘,减少磁盘IO
缓冲池以页为单位
free page:未使用的页
clean page:被使用的页,数据没有被修改过
dirty page:被使用的页,数据被修改过
Change Buffer(更改缓冲池):针对非唯一二级索引,如果要更改的数据不在缓存池中,则会先将数据保存在change buffer中,等将来读取时数据被加载到缓冲池后,再进行合并,减少因为调整索引树造成的磁盘IO
Log Buffer(日志缓冲区):保存要写入磁盘的日志数据(redo log(重做日志),undo log(撤销日志))
磁盘结构

事务
原理
持久性:通过redo log重做日志,在缓冲区刷回磁盘的时候发生错误进行数据恢复
原子性:通过undo log回滚日志,当事务失败时进行回滚(一起成功,一起失败)
MVCC
Multi-Version Concurrency Control,多版本并发控制
实现读取数据不用加锁。可以让读取数据同时修改,修改数据时同时可读取
解决并发通常的方案
- 使用共享锁和排他锁
- 通过对并发数据进行快照备份,从而达到无锁访问
MVCC就是通过保存数据的多个快照版本,通过版本号来确认要展示的数据
概念
当前读:读的是最新的数据(不可重复读)
快照读:每次select都生成一个快照读,事务里读的是第一个select查到的数据(可重复读)
隐藏字段
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 记录操作该数据事务的事务ID |
| DB_ROLL_PTR | 相当于一个指针,指向回滚段的undo日志 |
| DB_ROW_ID | 隐藏主键,没有指定主键时生成 |
undo log(回滚日志)
用于记录数据被修改前的信息。在表记录修改之前,会先把数据拷贝到undo log里,并且记录这个版本的事务id,如果事务回滚,即可以通过undo log来还原数据。
通过版本链的形式记录数据的历史版本,用于回滚事务、快照读等
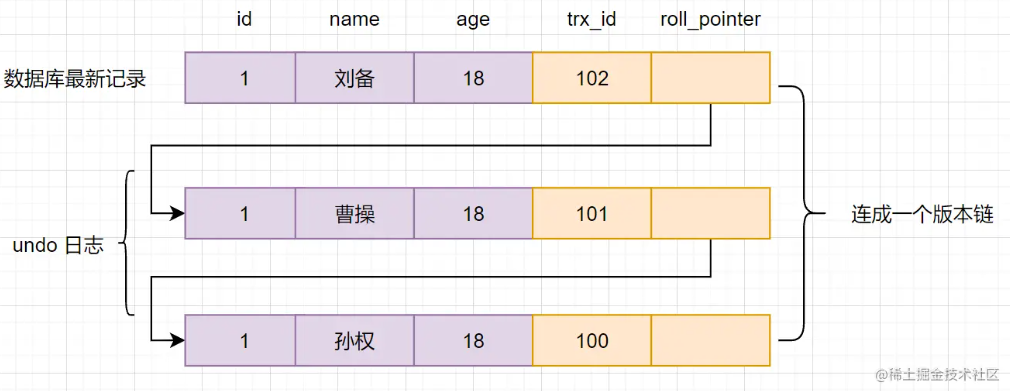
Read View
事务执行SQL语句时,产生的读视图,主要是用来做可见性判断的,即判断当前事务可见哪个版本的数据
read view主要属性
| 属性 | 说明 |
|---|---|
| m_ids | 当前系统中那些活跃(开启且未提交)的读写事务ID |
| min_limit_id | m_ids中的最小值 |
| max_limit_id | 最大事务ID+1 |
| creator_trx_id | 创建时的事务ID |
原理
读已提交级别下,事务中的每次select都会创建新的ReadView,会查找不在m_ids中的事务ID对应的历史数据
可重复读级别下,事务中只会在第一次select时创建ReadView,通过判断读取到的行的 DB_TRX_ID 与 DB_ROLL_PTR 字段指向的 undo log 回溯到事务开启前或当前事务最后一次更新的数据版本
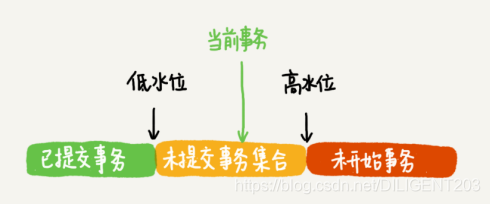
在修改数据时会出现幻读
SQL语句执行流程
查询语句
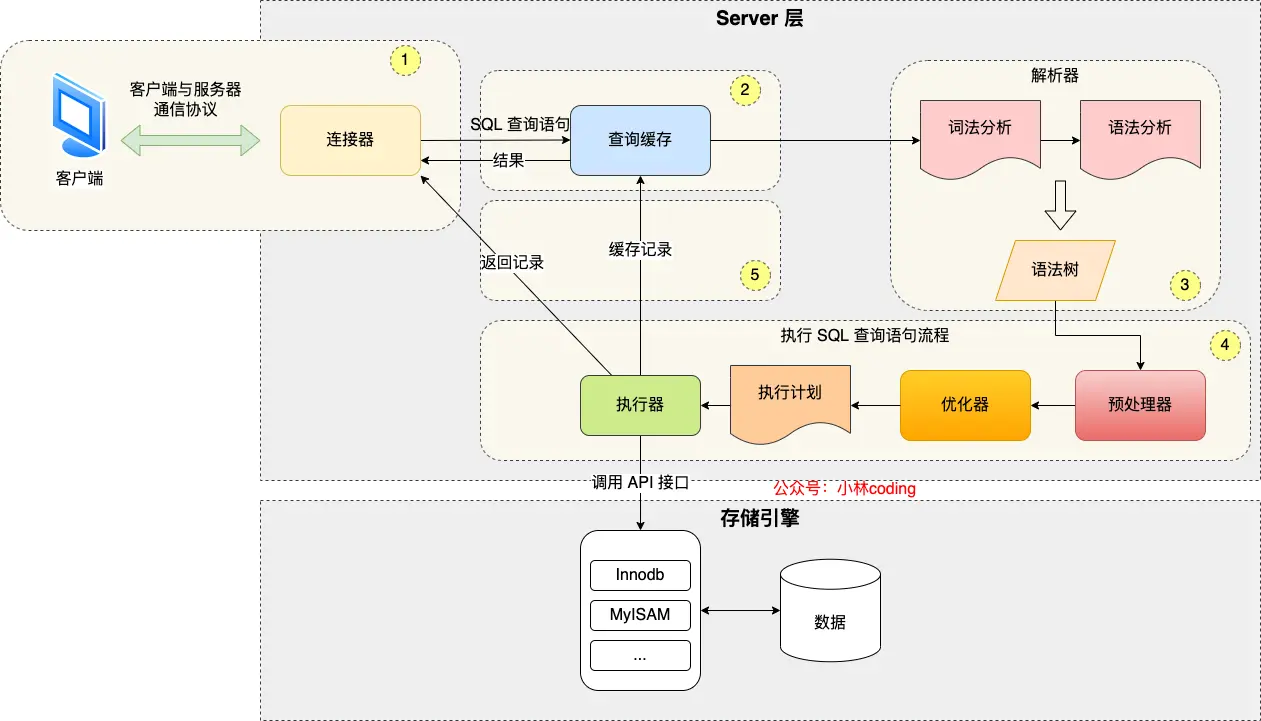
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列。 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
- 预处理阶段:检查表或字段是否存在;将
执行器和存储引擎的交互
主键索引查询
执行器调用存储引擎的查询接口,并把查询条件交给存储引擎;
存储引擎通过B+树找到符合条件的记录,返回给执行器;
执行器判断记录是否符合条件并返回给客户端;
循环以上步骤直到没有再查询到数据
全表查询
执行器调用存储引擎的查询接口;
存储引擎把一条记录返回给执行器;
执行器判断记录是否符合条件并返回给客户端;
循环以上步骤直到没有再查询到数据
索引下推
在使用联合索引时,和全表查询不同的是,会把查询条件也交给存储引擎;
当联合索引部分失效时,失效的字段由存储引擎来判断是否符合条件;
这样就不用回表查询出记录后再由执行器来判断了
索引下推能够减少二级索引的回表操作
存储行
存储位置
数据库表文件存储位置show variables like 'datadir'
5.7及之前版本的文件
.frm文件:存储表结构.idb文件(表空间):存储表数据
之后的版本
.idb文件(表空间):存储表结构和表数据
表空间结构
行:一条记录
页:16KB,每次读取磁盘里的记录都是以页为单位
- 页中的记录通过指针形成双向链表
- 记录分成了一个个组
- 页中包含页目录,目录中有多个槽,执行各个分组的最后一个记录。通过二分来定位到分组
区:1MB,由页构成
段:由多个区组成,分为索引段、数据段、回滚段等
行格式
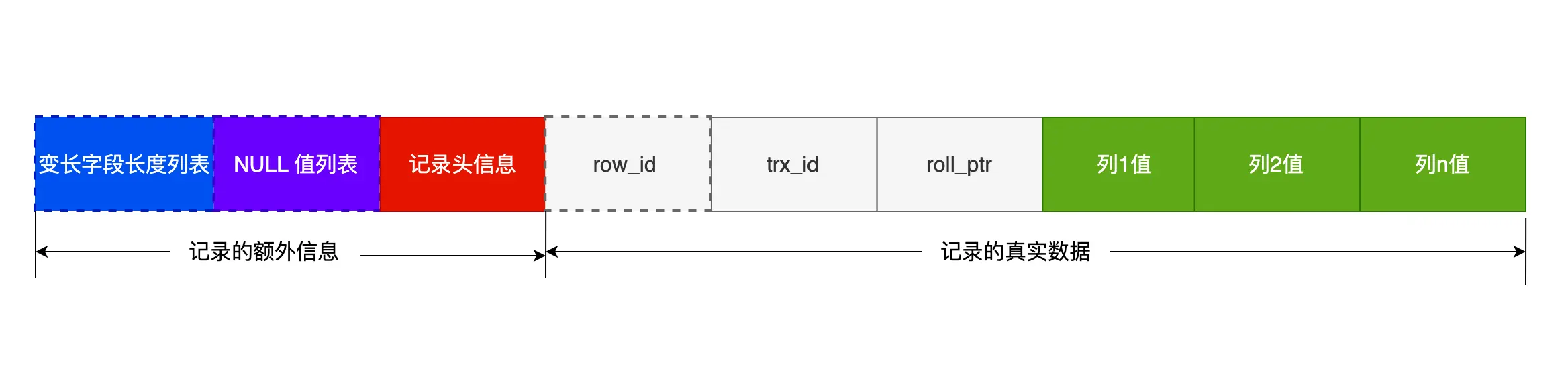
- 变长字段长度列表:记录每个变长字段(varchar、Text等)的长度
- NULL值列表:记录可以为空的字段是否为NULL值
- 记录头信息:记录是否被删除、下一条数据的指针等信息
- row_id:没有主键时的隐藏主键
- trx_id:创建该条记录的事务id
- roll_ptr:指向上一个版本的指针
因为指向下一条数据的指针是指到’记录头信息’和’row_id’中间的位置,所以为了方便查询,变长字段长度列表和NULL值列表的顺序和字段顺序相反。
一行记录的长度最大为65535B,而一页的大小为16KB,所以放不下的数据会放到溢出页中,原来的页中放指向溢出页的指针。