Redis
Redis
特点
Redis是一款基于内存的key-value结构数据库
默认端口号6379
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
使用场所
- 存放验证码、用户登录信息
- 对不常变化的数据进行缓存
安装及运行
官网下载压缩包 Redis官网
下载redis所需依赖
1
yum install -y gcc tcl上传压缩包,解压、编译、安装,默认安装在
/usr/local/bin1
2
3tar -zxvf redis-6.2.6.tar.gz
cd redis-6.2.6
make && make install
linux下运行redis
修改配置文件
1
2
3
4
5
6# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 123456其他常用配置
1
2
3
4
5
6
7
8
9
10# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"运行服务器端
1
2# 服务器端:运行redis的src目录下的redis-server文件
redis-server redis.conf远程连接
1
2
3要远程连接的话要把配置文件的bind 127.0.0.1注释起来
windows命令行: ./redis-cli.exe -h 远程ip地址 -p 6379ssss
出现 Error: 在驱动器 %1 上插入软盘。时要把linux上的redis的protected-mode设置成no
运行redis客户端
命令行客户端
1
2
3
4
5
6
7
8redis-cli [options] [commonds]
# 常见options
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1
-p 6379:指定要连接的redis节点的端口,默认是6379
-a 123456:指定redis的访问密码
# 测试
ping # 如果连接成功返回PONG图形化客户端
windows下运行redis
运行redis-server.exe文件即可
1 | |
Docker下运行redis
- 下载镜像:https://hub.docker.com/_/redis
- 创建容器
docker run --name redis -d -p 6379:6379 redis--name redis:给这个容器取名字-d:后台运行-p 6379:6379:把容器内的端口映射到宿主机的端口上,前一个是宿主机的端口,后一个是容器内的端口redis:使用的镜像名,如果本地没有redis的镜像,会自动下载最新版
数据类型
基本类型
- 字符串string
- 哈希 hash (适合存对象)
- 列表 list
- 集合 set
- 有序集合 sorted set
命令
通用命令
命令行help @generic查看帮助文档
| 命令 | 说明 |
|---|---|
| keys pattern | 查找符合模式pattern的key 模糊查询会影响效率,不建议生产环境使用 |
| exists key | 检查key是否存在 |
| type key | 返回key所存储的值得类型 |
| ttl key | 查看key的剩余有效时间 -2已失效,-1永久有效 |
| expire key seconds | 设置key的有效剩余时间 |
| del key | 删除key |
String
| 命令 | 说明 |
|---|---|
| set key value | 设置值 |
| get key | 获取值 |
| mset k1 v1 k2 v2 … | multi,批量设置值 |
| mget v1 v2 … | 批量获取值 |
| incr key | 让整型的key自增1 |
| incrby key step | 让整型的key自增自定义步长 |
| setex key seconds value | 设置值并指定过期时间(秒) |
| setnx key value | 当key不存在时才设置值 |
Hash
| 命令 | 说明 |
|---|---|
| hset key field value | (可以批量)设置key中字段field的值 |
| hget key field | (可以批量)获取key中字段field的值 |
| hdel key field | 删除key中字段field |
| hkeys key | 获取key中所有字段 |
| hvals key | 获取key中所有值 |
| hgetall key | 获取key中所有字段和值 |
| hincrby key field step | 自增 |
| hsetnx key field value | field不存在时才添加 |
List
类似java的LinkedList
| 命令 | 说明 |
|---|---|
| lpush key value1 [value2…] | 插入一个或多个值到列表左边 |
| lrange key start stop | 获取列表指定范围内的元素 |
| rpop key | 移除并获取列表最右边一个元素 |
| llen key | 获取列表长度 |
| brpop key1 [key2..] timeout | 在timeout时间里移除并获取列表最右一个元素 |
Set
| 命令 | 说明 |
|---|---|
| sadd key member1 [member2…] | 添加一个或多个元素 |
| smembers key | 返回所有元素 |
| scard key | 获取元素数 |
| sinter key1 [key2…] | 返回交集 |
| sunion key1 [key2…] | 返回并集 |
| sdiff key1 [key2…] | 返回差集 |
| srem key member1 [member2…] | 移除一个或多个元素 |
| sismember key member | 判断元素是否在集合中 |
Sorted Set
类似java的TreeSet
| 命令 | 说明 |
|---|---|
| zadd key score1 member1 [score2 member2…] | 添加一个或多个元素,或更新已有元素的分数 |
| zrange key start stop [withscores] | 获取指定区间元素 |
| zincrby key increment member | 对指定元素的分数加上增量increment |
| zrem key member1 [member2…] | 移除一个或多个元素 |
| zcount key min max | 统计score值在给定范围内的所有元素的个数 |
| zcard key | 获取sorted set中的元素个数 |
| zranke key member | 获取sorted set 中的指定元素的排名 |
key的层级关系
推荐key的命名方式为项目名:业务名:类型:id
RDM图形界面工具会自动根据: 来分包
java操作redis
jedis
jedis的方法名和redis的命令是一样的,方便学习,但是线程不安全
导入依赖
1
2
3
4
5
6
7
8
9
10
11
12<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.0</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 建立连接
jedis = new Jedis("47.96.80.163", 6378);
// 设置密码
jedis.auth("123456");
// 选择库,默认0
jedis.select(0);
}
@Test
void test() {
jedis.set("name", "zs");
String name = jedis.get("name");
System.out.println(name);
}
@AfterEach
void tearDown() {
// 关闭连接
if (jedis != null)
jedis.close();
}
}
遇到程序包redis.clients.jedis不存在时
jedis连接池
因为jedis是线程不安全的,所以可以使用jedis连接池来给每个线程分配一个jedis,从而避免因为多线程导致的问题
编写连接池工厂类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class JedisConnectionFactory {
private static JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8); // 最大数量
poolConfig.setMaxIdle(8); // 最大保存待命的数量
poolConfig.setMinIdle(0); // 最小保存待命的数量
poolConfig.setMaxWait(Duration.ofSeconds(200)); // 最大等待时间,超出时间就会销毁
// 创建连接池对象,参数:连接池配置、服务端ip、服务端端口、超时时间、密码
jedisPool = new JedisPool(poolConfig, "47.96.80.163", 6378, 1000, "123456");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}测试通过线程池获取jedis
1
2
3
4
5
6
7
8
9@BeforeEach
void setUp() {
// 建立连接
jedis = JedisConnectionFactory.getJedis();
// 设置密码
jedis.auth("123456");
// 选择库,默认0
jedis.select(0);
}
Spring Data Redis
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。
通过opsForXXX()方法获取操作某个数据类型的对象,再进行操作
导入坐标
1
2
3
4
5
6
7
8
9
10<!-- spring-data-redis依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 连接池依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>添加配置
1
2
3
4
5
6
7
8
9
10
11
12
13spring:
data:
redis:
host: 47.96.80.163
port: 6378
password: 123456
# 默认使用lettuce连接池,要使用jedis连接池需要导入jedis依赖
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000ms注入RedisTemplate测试
1
2
3
4
5
6
7
8
9
10
11
12@SpringBootTest
class SpringDataRedisDemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("aaa", "bbb");
System.out.println(redisTemplate.opsForValue().get("aaa"));
}
}
自定义序列化器
默认使用jdk的序列化器,可读性差,内存占用较大
编写配置类
使用到了json序列化器,可能要自己导入坐标
1
2
3
4
5<!--jackson-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 创建key序列化工具
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 创建value序列化工具
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
}测试
1
2
3
4
5
6@Test
void testUser() {
User user = new User("张三", 20);
redisTemplate.opsForValue().set("user:1", user);
System.out.println(redisTemplate.opsForValue().get("user:1"));
}redis中存的格式为
1
2
3
4
5{
"@class": "com.xw.springdataredisdemo.pojo.User",
"name": "张三",
"age": 20
}会额外存序列化的类信息,占据额外内存,可以使用StringRedisTemplate解决这个问题
StringRedisTemplate
StringRedisTemplate是RedisTemplate<String, String>的特化版本。它 简化了对 Redis 字符串(String)类型的操作,不需要手动序列化和反序列化。
可以直接使用 Java 的
String类型作为键和值
注入StringRedisTemplate,测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21@SpringBootTest
class SpringDataRedisDemoApplicationTests {
@Autowired
private StringRedisTemplate redisTemplate;
// JSON序列化工具
private ObjectMapper mapper = new ObjectMapper();
@Test
void testUser() throws JsonProcessingException {
User user = new User("张三", 20);
// 手动序列化为json
String json = mapper.writeValueAsString(user);
redisTemplate.opsForValue().set("user:1", json);
// 手动反序列化
String jsonUser = redisTemplate.opsForValue().get("user:1");
User u = mapper.readValue(jsonUser, User.class);
System.out.println(u);
}
}redis中存的格式为
1
2
3
4{
"name": "张三",
"age": 20
}
缓存
缓存更新
更新策略
内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
最佳实践方案
- 低一致性需求:使用redis的内存淘汰机制
- 高一致性需求:主动更新,并以超时剔除作为兜底方案
- 读操作
- 缓存未命中则查询数据库,并写入缓存,并设定超时时间
- 写操作
- 先写数据库再删缓存
- 读操作
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
解决方式
- 缓存空对象
- 原理:即使访问的对象不存在,也在缓存中存一份空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
- 布隆过滤
- 原理:在缓存前多加一层,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
缓存雪崩
在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
解决方案
互斥锁
- 原理:第一个查询未命中的线程去(上锁)查询数据库、重建缓存数据,其他线程再此期间等待,直到缓存更新
- 优点:没有额外内存消耗,保证一致性,实现简单
- 缺点:影响性能,可能有死锁风险
逻辑过期
- 原理:设置一个过期时间的key,当过期时不删除缓存,而是有一个额外的线程持有锁去进行重构数据,在此期间其他线程返回的是旧数据
- 优点:线程无需等待,性能较好
- 缺点:不能保证一致性,有额外内存消耗,实现复杂
互斥锁实例
定义获取锁、释放锁的方法
1
2
3
4
5
6
7
8
9
10
11private boolean tryLock(String key) {
// setIfAbsent只有不存在时才放入值,以此来实现互斥锁
// 尝试获取锁
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
// 通过BooleanUtil,防止拆箱时空指针
return BooleanUtil.isTrue(flag);
}
private void unLock(String key) {
stringRedisTemplate.delete(key);
}使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public Shop queryWithPassMutex(Long id) {
// 从redis中查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
if ("".equals(shopJson)) {
return null;
}
// 防止缓存击穿
String lockKey = "lock:shop:" + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
if (!isLock) {
Thread.sleep(50);
return queryWithPassThrough(id);
}
// 没有缓存,从数据库中取数据
shop = this.getById(id);
if (shop == null) {
// 将空对象保存到redis,防止缓存穿透
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
return shop;
}
逻辑过期实例
定义获取锁、释放锁的方法
1
2
3
4
5
6
7
8
9
10
11private boolean tryLock(String key) {
// setIfAbsent只有不存在时才放入值,以此来实现互斥锁
// 尝试获取锁
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
// 通过BooleanUtil,防止拆箱时空指针
return BooleanUtil.isTrue(flag);
}
private void unLock(String key) {
stringRedisTemplate.delete(key);
}定义重建缓存的方法
1
2
3
4
5
6
7
8
9public void saveShop2Redis(Long id, Long expireSeconds) {
Shop shop = this.getById(id);
// 封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
// 写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40@Resource
private StringRedisTemplate stringRedisTemplate;
// 固定大小的线程池
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithPassLogicalExpire (Long id) {
// 从redis中查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
if (StrUtil.isBlank(shopJson)) {
return null;
}
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
// 判断是否过期
LocalDateTime expireTime = redisData.getExpireTime();
if (expireTime.isAfter(LocalDateTime.now())) {
// 未过期,直接返回
return shop;
}
// 已过期,重建缓存
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
if (isLock) {
// 开启新线程
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 重建缓存
this.saveShop2Redis(id, 30L);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
unLock(lockKey);
}
});
}
// 返回旧数据
return shop;
}
使用
封装工具类
具有的功能:
- 存
- 将任意对象序列化为json存到string类型的key的缓存中,并设置TTL过期时间
- 将任意对象序列化为json存到string类型的key的缓存中,并设置逻辑过期时间,用于处理缓存击穿问题
- 取
- 根据key查询缓存,并反序列化为指定对象,利用缓存空值的方法解决缓存穿透问题
- 根据key查询缓存,并反序列化为指定对象,利用逻辑过期解决缓存击穿问题
1 | |
优惠券秒杀
全局id生成器
是一种在分布式系统下用来生成全局唯一ID的工具
id(Long型,64位)的结构可以设计成:
符号位(1位,为0) :时间戳(31位,以秒为单位) :序列号(32位)
作用:
- 增加id的复杂性,防止被猜出规律
- 唯一性,安全性
Redis自增实现全局id生成器
1 | |
测试
1 | |
超卖问题
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁
通常有两种解决方案
- 悲观锁:认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行
- 乐观锁:认为线程安全问题不一定会发生,只在更新数据的时候去判断数据是否被其他线程修改
实例
1 | |
分布式锁
满足分布式系统或集群模式下多进程可见并且互斥的锁
在集群部署的时候不能使用synchronized作为锁,每个tomcat都有一个属于自己的jvm,锁的时候不是锁的同一个对象,导致synchronized失效
分布式锁应满足的条件:
可见性:多个线程都能看到相同的结果,注意:这个地方说的可见性并不是并发编程中指的内存可见性,只是说多个进程之间都能感知到变化的意思
互斥:互斥是分布式锁的最基本的条件,使得程序串行执行
高可用:程序不易崩溃,时时刻刻都保证较高的可用性
高性能:由于加锁本身就让性能降低,所有对于分布式锁本身需要他就较高的加锁性能和释放锁性能
基于Redis实现分布式锁
1 | |
第一版锁,在业务时间超过锁过期时间时,存在锁被其他jvm的线程误删的风险
1 | |
第二版锁,解决锁误删的问题
1 | |
原子性问题
执行完业务,要释放锁的时候,先判断锁标识是否一致,然后再释放锁
此时若获取锁标识后出现阻塞,在阻塞期间锁过期并被其他jvm的线程获取
当阻塞结束就有可能将锁误删除
获取锁标识和释放锁不是原子性的
解决方式
通过Lua脚本实现原子性操作多条命令
客户端调用脚本
1 | |
java调用lua脚本
创建lua脚本
1 | |
加载lua脚本
1 | |
使用脚本
1 | |
Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
使用
引入依赖
1
2
3
4
5<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>配置Redisson客户端
1
2
3
4
5
6
7
8
9
10@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
//获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("anyLock");
//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS);
//判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
Redission分布式锁原理
可重入:利用hash结构记录线程id和重入次数
可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
主从一致性:多个独立的Redis节点,必须在所有节点都获取重入锁,蔡栓获取锁成功
优化秒杀
思路:
将耗时比较短的逻辑判断放入到redis中,比如是否库存足够,比如是否一人一单,这样的操作,只要这种逻辑可以完成,就意味着我们是一定可以下单完成的,我们只需要进行快速的逻辑判断,根本就不用等下单逻辑走完,我们直接给用户返回成功, 再在后台开一个线程,后台线程慢慢的去执行queue里边的消息
实例:
在新增秒杀券的时候,将库存信息保存到redis中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15@Override
@Transactional
public void addSeckillVoucher(Voucher voucher) {
// 保存优惠券
save(voucher);
// 保存秒杀信息
SeckillVoucher seckillVoucher = new SeckillVoucher();
seckillVoucher.setVoucherId(voucher.getId());
seckillVoucher.setStock(voucher.getStock());
seckillVoucher.setBeginTime(voucher.getBeginTime());
seckillVoucher.setEndTime(voucher.getEndTime());
seckillVoucherService.save(seckillVoucher);
// 保存优惠券库存到redis中
stringRedisTemplate.opsForValue().set(RedisConstants.SECKILL_STOCK_KEY + voucher.getId(), voucher.getStock().toString());
}将判断库存和一人一单的判断逻辑写到lua脚本中,实现快速判断是否能购买
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22local voucherId = ARGV[1]
local userId = ARGV[2]
local stockKey = 'seckill:stock:' .. voucherId
local orderKey = 'seckill:order:' .. voucherId
-- 判断库存是否充足
if (tonumber(redis.call('get', stockKey)) <= 0) then
-- 库存不足,返回1
return 1
end
-- 判断当前用户是否已下过单(一人一单)
if (redis.call('sismember', orderKey, userId) == 1) then
-- 以下过单,返回2
return 2
end
-- 扣除库存,下单
redis.call('incrby', stockKey, -1)
redis.call('sadd', orderKey, userId)
return 01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30private static final DefaultRedisScript<Long> SECKILL_SCRIPT;
static {
SECKILL_SCRIPT = new DefaultRedisScript<>();
SECKILL_SCRIPT.setLocation(new ClassPathResource("script/seckill.lua"));
SECKILL_SCRIPT.setResultType(Long.class);
}
IVoucherOrderService proxy;
@Override
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// 执行lua脚本判断
Long result = stringRedisTemplate.execute(
SECKILL_SCRIPT,
Collections.emptyList(), // keys
voucherId.toString(), userId.toString() //values
);
int r = result.intValue();
if (r != 0) {
return Result.fail(r == 1 ? "库存不足" : "不能重复下单");
}
// 保存到阻塞队列(之后通过lua脚本完成)
// 获取代理对象
proxy = (IVoucherOrderService) AopContext.currentProxy();
orderTasks.add(voucherOrder);
return Result.ok(orderId);
return Result.ok(orderId);
}下单时将创建/保存订单任务放到(jdk的)阻塞队列中,异步执行任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48// 阻塞队列和执行下单的线程
private BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024);
private static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
// 类初始化完后会调用此方法
@PostConstruct
private void init() {
// 开启处理阻塞队列的线程
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
}
private class VoucherOrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 获取阻塞队列里的订单,如果队列为空则会阻塞住
VoucherOrder voucherOrder = orderTasks.take();
// 创建订单
handleVoucherOrder(voucherOrder);
} catch (InterruptedException e) {
log.error("处理订单异常", e);
}
}
}
}
@Transactional
public void createVoucherOrder(VoucherOrder voucherOrder) {
Long userId = voucherOrder.getUserId();
// 一人一单
Integer count = this.query().eq("user_id", userId)
.eq("voucher_id", voucherOrder.getVoucherId()).count();
if (count > 0) {
log.error("用户已经购买过一次");
}
// 扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherOrder.getVoucherId())
.gt("stock", 0) // 防止超卖
.update();
if (!success)
log.error("库存不足");
// 保存订单
this.save(voucherOrder);
}
Redis消息队列
概念
消息队列模型主要包括的三个角色:
- 生产者:发送消息到消息队列
- 消息队列:存储和管理消息,也称为消息代理
- 消费者:从消息队列获取消息并处理
Redis提供了三种不同的方式来实现消息队列:
- list:基于List结构模拟消息队列
- PubSub:基于点对点消息模型(发布订阅)
- Stream:比较完善的消息队列模型
基于List实现消息队列
| 指令 | 说明 |
|---|---|
| LPUSH/RPUSH keys values | 往双端队列存数据 |
| LPOP/RPOP | 从双端队列取数据并删除 |
| BLPOP/BRPOP | 取数据,没有数据的时候会等待 |
缺点:
- 无法避免消息丢失
- 只支持单消费者
基于PubSub的消息队列
| 指令 | 说明 |
|---|---|
| SUBSCRIBE channels | 订阅频道 |
| PUBLISH channel msg | 向一个频道发送消息 |
| PSUBSCRIBE pattern | 订阅与pattern格式匹配的所有频道 ?:匹配一个字符 *:匹配0到多个字符 [ab]:匹配括号里的字符 |
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出会数据丢失
基于Stream的消息队列
| 指令 | 说明 |
|---|---|
| XADD | 发送消息 |
| XREAD | 读取消息,不会删除 |


特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
实例
基于Redis的Stream结构作为消息队列,实现异步秒杀下单
创建消息队列
1
XGROUP create stream.orders g1 0 mkstream修改判断是否有抢购资格的lua脚本,发送消息到消息队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25local voucherId = ARGV[1]
local userId = ARGV[2]
local orderId = ARGV[3]
local stockKey = 'seckill:stock:' .. voucherId
local orderKey = 'seckill:order:' .. voucherId
-- 判断库存是否充足
if (tonumber(redis.call('get', stockKey)) <= 0) then
-- 库存不足,返回1
return 1
end
-- 判断当前用户是否已下过单(一人一单)
if (redis.call('sismember', orderKey, userId) == 1) then
-- 以下过单,返回2
return 2
end
-- 扣除库存,下单
redis.call('incrby', stockKey, -1)
redis.call('sadd', orderKey, userId)
-- 发送消息到队列中
redis.call('xadd', 'stream.orders', '*', 'userId', userId, 'voucherId', voucherId, 'id', orderId)
return 0编写处理消息逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56private class VoucherOrderHandler implements Runnable {
String queueName = "stream.orders";
@Override
public void run() {
while (true) {
try {
// 获取消息队列里的订单,如果队列为空则会阻塞住
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
if (list == null || list.isEmpty()) {
// 没有读到消息,继续下一次循环
continue;
}
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
// 创建订单
handleVoucherOrder(voucherOrder);
// ack确认
stringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
handlePendingList();
}
}
}
private void handlePendingList() {
while (true) {
try {
// 获取消息队列里的订单,如果队列为空则会阻塞住
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1),
StreamOffset.create(queueName, ReadOffset.from("0"))
);
if (list == null || list.isEmpty()) {
// 没有读到消息,结束循环
break;
}
MapRecord<String, Object, Object> record = list.get(0);
Map<Object, Object> values = record.getValue();
VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);
// 创建订单
handleVoucherOrder(voucherOrder);
// ack确认
stringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId());
} catch (Exception e) {
log.error("处理订单异常", e);
}
}
}
}
点赞
通过redis存哪些用户点赞了哪些文章,实现一篇文章一个用户只能点赞一次
点赞时调用的方法
1 | |
通过id查询文章时调用的方法
1 | |
查询热门文章时调用的方法
1 | |
查询点赞顺序
1 | |
关注
通过set集合的查看交集功能实现查找共同关注
1 | |
推送
推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
Feed流有常见两种模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
Timeline模式的实现方案有三种:
- 拉模式:也叫做读扩散。被关注人发送消息后会保存到自己的邮箱,用户自己去拉取关注的人的收件箱里的消息
- 优点:节约空间
- 缺点:比较延迟,要拉的消息多时对服务器有较大压力
- 推模式:也叫做写扩散。被关注人发送消息后会主动写到关注人的邮箱中
- 优点:实效快
- 缺点:内存占用大
- 推拉结合:也叫做读写混合。对粉丝少的被关注人使用推模式;对于粉丝多的被关注人,对活跃粉丝使用推模式,对其他粉丝使用拉模式
实例
推模式,用sortedSet作为收件箱
推给粉丝消息
1 | |
粉丝查看消息
通过滚动分页实现
滚动分页:从上一次查到的消息开始分页,避免有新消息插入导致又拿到上次已经拿到的消息
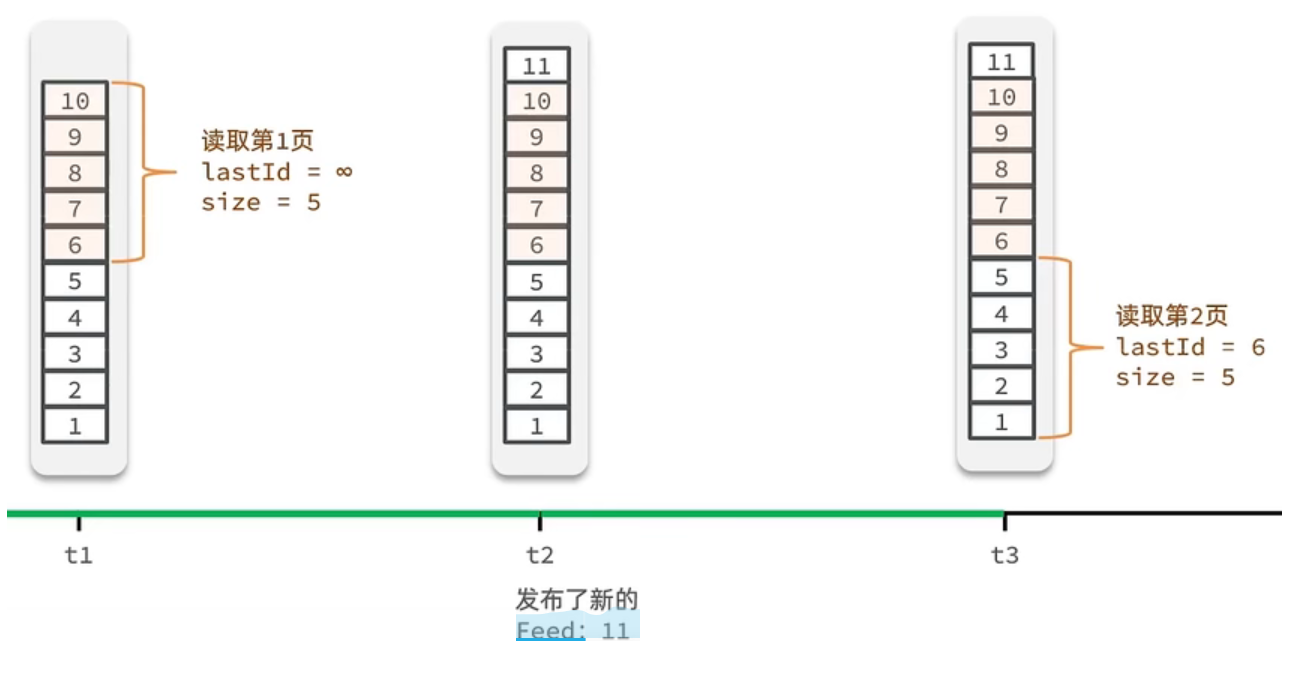
1 | |
附近
GEO数据类型:GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据,底层基于SortedSet
| 指令 | 说明 |
|---|---|
| GEOADD | 添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member) |
| GEODIST | 计算指定的两个点之间的距离并返回 |
| GEOHASH | 将指定member的坐标转为hash字符串形式并返回 |
| GEOPOS | 返回指定member的坐标 |
| GEORADIUS | 指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃 |
| GEOSEARCH | 在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能 |
| GEOSEARCHSTORE | 与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能 |
实例
按分类导入店铺id和坐标到redis
1 | |
查询附近店铺及距离,注意:redis版本要在6.2以上,否则使用不了GEOSEARCH指令
1 | |
签到
通过二进制位上的0和1表示当天是否有签到
使用Redis的BitMap数据结构实现,BitMap基于String实现
| 指令 | 说明 |
|---|---|
| SETBIT | 向指定位置(offset)存入一个0或1 |
| GETBIT | 获取指定位置(offset)的bit值 |
| BITCOUNT | 统计BitMap中值为1的bit位的数量 |
| BITFIELD | 操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值 |
| BITFIELD_RO | 获取BitMap中bit数组,并以十进制形式返回 |
| BITOP | 将多个BitMap的结果做位运算(与 、或、异或) |
| BITPOS | 查找bit数组中指定范围内第一个0或1出现的位置 |
实例
签到
1 | |
统计连续签到次数
1 | |
UV
Unique Visitor(独立访客量):一天同一个人访问网站记录一次
Page View(点击量):访问一个页面就记录一次
Hyperloglog(HLL):概率算法,用于确定非常大的集合的基数,对集合大小的测量有一定的误差
Redis中HLL是基于string结构实现的,内存占用很小
| 指令 | 说明 |
|---|---|
| PFADD key ele… | 添加元素 |
| PFCOUNT key | 获取大小 |
java中使用stringRedisTemplate.opsForHyperLogLog()来操作
分布式缓存
持久化
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),备份时是替换整个rdb文件
什么时候会RDB持久化:
执行save命令,会使用主进程持久化,在此期间其他命令都会阻塞
执行bgsave(异步持久化)命令
停机时自动save
触发RDB条件,执行bgsave(配置文件中设置)
1
2
3
4# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
相关配置
1
2
3
4
5
6
7
8# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
AOF持久化
AOF全称为Append Only File(追加文件),记录所有写命令到aof中
开启aof
1
2
3
4
5
6# 禁用rdb
save ""
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"持久化频率
1
2
3
4
5
6# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no重写命令,AOF文件执行重写功能,用最少的命令达到相同效果,以压缩文件大小。
BGREWRITEAOF重写配置
1
2
3
4# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
分布式锁
在单体项目下保证原子性可以使用synchronized,在分布式下就无法使用。
可以使用mysql、redis等来实现多线程下的锁。基本原理是根据id的唯一性来控制不同机器中的进程对资源的访问
实现方式1
setnx命令:当不存在时才设置值
expire命令:设置超时时间
获取锁时:
1 | |
释放锁时:
1 | |
缺陷:
当一个jvm的线程获取锁后、设置超时时间前挂了,就会导致死锁
实现方式2
使用
set key value ex timeout nx OK来让set和expire命令是一个原子操作或者也可以使用lua脚本实现
获取锁时:
1 | |
释放锁时:
如果释放锁前判断锁是自己的锁,但判断完锁超时了,此时就有可能会释放掉别人的锁,需要通过lua脚本使判断锁和释放锁是原子操作
1 | |
缺陷:
自己实现太麻烦了
实现方式3
通过Redisson实现,Redisson帮忙实现了分布式锁
1 | |
读写分离
windows下案例:配置两台redis,一主一从
创建两个文件夹
6379、6380,将配置文件redis.windows.conf各复制到文件夹中一份各创建
data文件夹用于存放数据文件6379(主服务器)中要改的配置1
2
3
4
5
6
7
8# 端口
port 6379
# 数据保存的文件夹
dir E:\redis\6379\data
# 密码
requirepass 1234566380(从服务器)中要改的配置1
2
3
4
5
6
7
8
9
10
11# 端口
port 6380
# 数据保存的文件夹
dir E:\redis\6380\data
# 主服务器密码
masterauth 123456
# 从属于哪台服务器
replicaof 127.0.0.1 6379redis-server.exe 配置文件路径启动两台redisspringboot中配置类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* redis序列化器配置
*/
@Configuration
public class RedisConfig {
@Bean
public RedisConnectionFactory redisConnectionFactory() {
LettuceClientConfiguration clientConfiguration = LettuceClientConfiguration.builder()
.readFrom(ReadFrom.REPLICA) // 读操作都找从节点
.build();
RedisStaticMasterReplicaConfiguration configuration = new RedisStaticMasterReplicaConfiguration("127.0.0.1", 6379);
configuration.addNode("127.0.0.1", 6380);
configuration.setPassword("123456");
return new LettuceConnectionFactory(configuration, clientConfiguration);
}
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 创建key序列化工具
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 创建value序列化工具
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
}